[1] -2.200985Tema 4
Introducción al contraste de hipótesis
22/mayo/2026
3 Elementos de un test de hipótesis
Importancia de conocer la distribución del estadístico de contraste
- Conocer la distribución del estadístico de contraste permite valorar su magnitud ante un problema dado.
- Recordemos que la distribución de \(\small t_{\text{exp}}\) la establece la hipótesis nula.
- Como la distribución t es simétrica, lo que importa no es el signo de \(\small t_{\text{exp}}\), sino su magnitud.

- Si \(\small t_{\text{exp}}\) toma un valor extremo en la distribución establecida por \(\small \text{H}_0\), esto significa que es un valor improbable, lo que se traduce en una discrepancia entre los valores empíricos y lo que propone la hipótesis nula \(\leftarrow\) Esto nos llevaría a rechazar \(\small \text{H}_0\).
- Si, por el contrario, \(\small t_{\text{exp}}\) tomara un valor próximo a cero, por ejemplo \(\small t_{\text{exp}}=0.5\), entonces sería un valor muy probable bajo esta distribución, lo que indica que la hipótesis nula explica bien los datos observados \(\leftarrow\) En este caso no podríamos rechazar \(\small \text{H}_0\).
- Pero, ¿cómo decidir cuándo \(\small t_{\text{exp}}\) es extremo?
3.1 Decisión basada en la magnitud del estadístico de contraste
Regiones crítica y de aceptación
Al fijar el nivel de significación, se está dividiendo el conjunto de valores que puede tomar el estadístico de contraste en dos regiones:
- La región de aceptación (RA) del test es el conjunto de valores del estadístico de contraste que llevan a NO rechazar la hipótesis nula.
- La región crítica (RC), o de rechazo, del test es el conjunto de valores del estadístico de contraste que se consideran improbables y llevan a rechazar la hipótesis nula.
- Si el test es bilateral la región crítica se reparte en las dos colas

- ¿Cómo se establece la frontera entre estas regiones?
- En un test bilateral, al fijar el valor de \(\small \alpha\) no hay más que determinar los percentiles \(\small t_{\alpha/2}\) y \(\small t_{1-\alpha/2}\)
- Por simetría de la distribución t, estos percentiles tendrán el mismo valor pero con distinto signo.
- A estos percentiles se les suele denominar cantidad teórica (se suele considerar el valor con signo positivo)
- Decisión con el test
- Si \(\small |t_{\text{exp}}| \le |t_{\alpha/2}|\) \(\leftarrow\) El estadístico de contraste pertenece a la región de aceptación de la hipótesis nula, por tanto, la decisión es no rechazar \(\small \text{H}_0\) al nivel de significación \(\small \alpha\).
- Si \(\small |t_{\text{exp}}| > |t_{\alpha/2}|\) \(\leftarrow\) El estadístico de contraste pertenece a la región crítica, por tanto, la decisión es rechazar \(\small \text{H}_0\) al nivel de significación \(\small \alpha\).
eGFR (III). Decisión basada en el nivel de significación
![]() Si fijamos un nivel de significación del 5%, es decir \(\small\alpha=0.05\), el percentil \(\small t_{0.05/2}\) de la distribución t de Student con 11 grados de libertad se obtiene:
Si fijamos un nivel de significación del 5%, es decir \(\small\alpha=0.05\), el percentil \(\small t_{0.05/2}\) de la distribución t de Student con 11 grados de libertad se obtiene:

Decisión: Como \(\small |t_{\text{exp}}|=3.41 > |t_{\alpha/2}|=2.20\) \(\rightarrow\) El valor que toma el estadístico de contraste pertenece a la región crítica. Por tanto, rechazamos \(\small \text{H}_0\) a un nivel de significación \(\small \alpha\) del 5%.
Si el estadístico hubiera tomado, por ejemplo, el valor \(\small t_{\text{exp}}=-2.00\), al encontrarse dentro de la región de aceptación, habríamos concluido que –a un nivel de significación \(\small \alpha\) del 5%– la información muestral es compatible con la hipótesis nula, por tanto, no podemos rechazarla.
RC en los test unilaterales

(c) Pedro Femia bajo licencia  CC-BY-SA
CC-BY-SA
CC-BY-SA
En el ejemplo de eGFR, la media muestral fue \(\small \bar{x}=85,67\), este valor sería incompatible con la hipótesis alternativa \(\small\text{H}_1:\mu>\mu_0=90\), puesto que es \(\small \bar{x}<\mu_0\) (observemos al ser \(\small t_{\text{exp}}\) negativo, nunca podría pertenecer a la región crítica de la cola derecha).
3.2 Decisión basada en la probabilidad asociada al estadístico de contraste
El valor p
El valor p (en inglés p‑value) es la probabilidad, calculada bajo el supuesto de que la hipótesis nula es cierta, de obtener un resultado\(\small ^*\) al menos tan extremo como el observado en la muestra.
* Al aludir a un resultado debe entenderse al valor tomado por el estadístico de contraste.
El valor p mide cuánta evidencia aportan los datos en contra de la hipótesis nula:
- Valor p pequeño → El resultado observado es muy improbable si \(\small \text{H}_0\) es cierta → evidencia contra \(\small \text{H}_0\).
- Valor p grande → El resultado observado es probable bajo la \(\small \text{H}_0\) → no hay evidencia suficiente para rechazarla.

Las áreas en rojo representan el valor p. Las líneas en rojo indican el valor del estadístico de contraste \(\small t_{\text{exp}}\).
Dada la simetría de la distribución, en los test bilaterales el área en rojo es el doble que en los unilaterales, ya que hay que contemplar las dos colas.
(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
Decisión basada en el valor p:
- Si \(\small p\le\alpha\) → se dice que el test es significativo, se rechaza la hipótesis nula.
- Si \(\small p>\alpha\) → se dice que el test NO es significativo, no se puede rechazar la hipótesis nula.
Como veremos más adelante, valores de \(\small p>\alpha\) pero cercanos al nivel de significación generan una duda razonable: No se puede rechazar \(\small \text{H}_0\) ¿por que es cierta, o por que no hay suficiente evidencia (tamaño muestral) para poder rechazarla?
eGFR (III). Decisión basada en el valor p
Recordemos que habíamos
- Fijado el nivel de significación \(\small \alpha=0.05\) (5%)
- Obtenido \(\small t_{\text{exp}}=-3.41\)
![]() Calculamos el valor P como la probabilidad de obtener un valor tan extremo, o más, que \(\small t_{\text{exp}}=-3.41\) bajo la distribución establecida por \(\small \text{H}_0\). Esto lo hacemos determinando qué percentil representa el valor \(\small -3.41\)
Calculamos el valor P como la probabilidad de obtener un valor tan extremo, o más, que \(\small t_{\text{exp}}=-3.41\) bajo la distribución establecida por \(\small \text{H}_0\). Esto lo hacemos determinando qué percentil representa el valor \(\small -3.41\)
Pero nuestro test es bilateral, por tanto, tenemos que contemplar también la otra cola. Como la distribución es simétrica, basta con multiplicar el valor anterior por dos:
Si hubiera sido \(\small t_{\text{exp}}\) positivo, por ejemplo \(\small t_{\text{exp}}=3.41\), al estar situado en la cola derecha, el valor p se puede obtener de dos formas equivalentes
Por supuesto, en el test bilateral hay que multiplicar iguamente los valores obtenidos por dos: \(\small p= 0.0029\times 2=0.0058\)
Conclusión:
Suponiendo cierta la hipótesis nula, la probabilidad de observar un valor tan extremo o más que \(\small t_{\text{exp}}=-3.41\) es \(\small p=0.0058\) (el 5.8 por mil). Como \(\small p<\alpha\) consideramos, o bien que estamos observando un suceso muy raro, o bien que la hipótesis nula no explica los datos observados.
Nunca pensaremos que estamos ante un suceso raro, por tanto concluimos que la hipótesis nula no explica los datos observados, de manera que rechazamos esta hipótesis.
Esta conclusión la escribiríamos en un informe de forma parecida a la que sigue:
(…) en los pacientes con enfermedad renal crónica, se encontró una diferencia significativa entre el valor medio observado y el valor normativo para el filtrado glomerular estimado (p=0.006) (…)
La literatura científica esta llena da valores p, por ejemplo Song et al (2009)
3.3 Error de tipo II y potencia de un test
Error de tipo II
Anteriormente consideramos el error que se comete al decidir rechazar \(\small \text{H}_0\) cuando es cierta. Se trataba del error de tipo I y su probabilidad se expresaba como
\[ \alpha = \Pr\left(\text{rechazar H}_0 | \text{es cierta H}_0\right) \]
Pero, también podemos cometer un error cuando decidimos no rechazar \(\small \text{H}_0\) cuando en realidad es falsa. A este error se le denomina error de tipo II, y su probabilidad se expresa como
\[ \beta = \Pr\left(\text{aceptar H}_0 | \text{no es cierta H}_0\right) \]
Así, si la decisión es
- Rechazar \(\small \text{H}_0\), el error que se puede cometer es el de tipo I.
Su probabilidad es \(\small \alpha\) y su valor máximo queda establecido por el investigador al fijar el nivel de significación. - Aceptar \(\small \text{H}_0\), el error que se puede cometer es el de tipo II.
Su probabilidad es \(\small \beta\) y ¡es desconocida!.

la hipótesis alternativa no establece ninguna de forma concreta.
Dada una posible distribución bajo \(\small \text{H}_1\), podríamos conocer la magnitud de \(\small \beta\).
El problema es que no sabemos donde localizar esa distribución.
(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
De qué depende la potencia de un test
La potencia –y en consecuencia también la magnitud del error de tipo II– depende fundamentalmente de tres factores:
Del própio fenómeno
Es decir, de lo alejada que esté la distribución asociada a \(\small \text{H}_1\) de la propuesta por \(\small \text{H}_0\).
Para \(\small \alpha = 0.05\)

(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
Del nivel de significación \(\alpha\) fijado de antemano
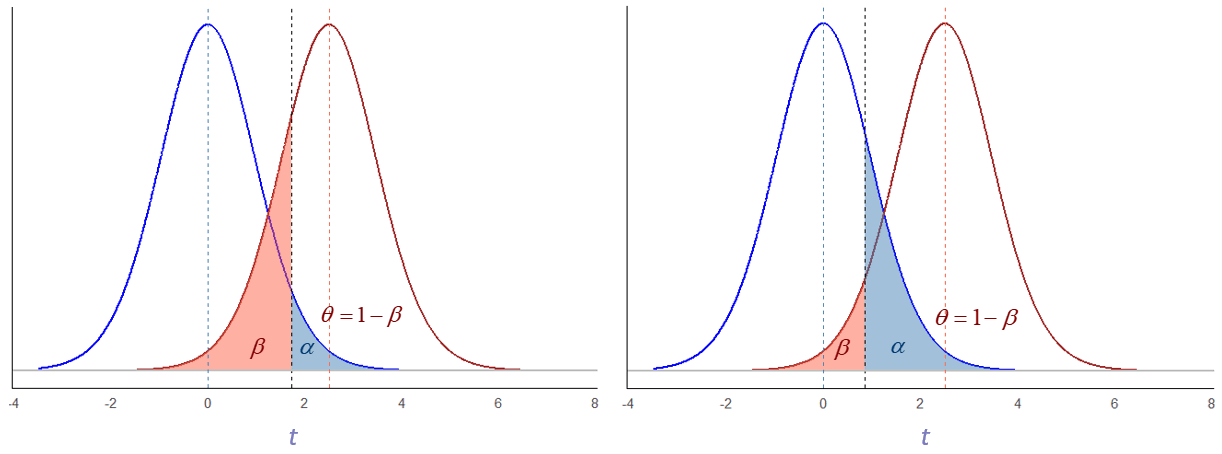
(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
Del tamaño de muestra disponible
Para \(\small \alpha = 0.05\)

por tanto, aumenta la potencia. A la izquierda, \(\small n=20\); a la derecha \(\small n=200\).
(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
4 Relación de los test de hipótesis con otros métodos inferenciales
Test de hipótesis y test de diagnóstico clínico
Se puede establecer una analogía entre los contrastes de hipótesis y los test de diagnóstico clínico que permite ganar en comprensión conceptual.
(c) Pedro Femia bajo licencia CC-BY-SA
CC-BY-SA
| Contraste de hipótesis (Estadística) | Test diagnóstico (Clínica / Enfermería) | Interpretación |
|---|---|---|
| Población de estudio | Conjunto de pacientes | El ámbito donde se quiere tomar una decisión |
| Muestra | Paciente individual | Unidad sobre la que se aplica el test |
| Hipótesis nula (\(\small \text{H}_0\)) | Paciente sano (ausencia de enfermedad) | Situación asumida por defecto |
| Hipótesis alternativa (\(\small \text{H}_1\)) | Paciente enfermo | Situación que requiere evidencia para ser aceptada |
| Estadístico de contraste | Resultado del test (biomarcador, prueba) | Información observada para tomar la decisión |
| Región de aceptación | Valores que se consideran clínicamente normales | Valores aceptables para lo que se asume por defecto |
| Región crítica | Valores que se consideran patológicos | Valores discrepantes con lo que se asume por defecto |
| Nivel de significación (\(\small \alpha\)) | Probabilidad de falso positivo | Riesgo aceptado de diagnosticar enfermedad en un sano |
| Error tipo I | Falso positivo | Declarar enfermo a un sano / declarar un efecto cuando no lo hay |
| Error tipo II (\(\small \beta\,\)) | Falso negativo | No detectar la enfermedad/efecto cuando realmente existe |
| Potencia (\(\small \theta=1-\beta\,\)) | Sensibilidad diagnóstica | Capacidad para detectar un efecto/enfermedad real |
| Valor p | Evidencia contra el estado sano | Compatibilidad de los datos con la ausencia de enfermedad |
| Decisión estadística | Decisión clínica | El test informa, pero no decide por sí solo |
Un contraste de hipótesis no “demuestra” nada, igual que un test no diagnostica por sí solo: ambos aportan evidencia para una decisión clínica o científica.

 .
.