Tema 2
Descripción estadística
22/mayo/2026
1 Introducción
¿Es necesario resumir los datos? La Matriz de casos x variables

- ¿hay más hombres o mujeres?
- ¿Qué edades han sido observadas?
- ¿Cuantos sujetos fuman?
- \(\dots\)
En general, cualquier estudio va a manejar grandes volúmenes de información.
- La síntesis de datos permite
- Detectar errores y valores atípicos (primer paso imprescindible antes de cualquier análisis).
- Caracterizar adecuadamente la muestra o los distintos subgrupos clínicos.
- Identificar patrones relevantes para la práctica enfermera, como distribuciones anómalas, asimetrías o variabilidad excesiva.
- La síntesis constituye la base de la inferencia, porque permite:
- Comparar de forma válida las características entre grupos de pacientes.
- Identificar posibles asociaciones entre variables.
- Facilitar la toma de decisiones fundamentadas en la evidencia cuantitativa.
4 Diagramas de frecuencias
- Comprobar visualmente la forma de la distribución es clave en el análisis de datos
- Los diagramas de frecuencias permiten apreciar la forma de la distribución; en particular, un aspecto clave es su simetría.
- Los diagramas ayudan a identificar la presencia de valores extremos y en qué partes se agrupan los datos.
- El tipo de diagrama depende del tipo de la variable.
- Diagramas clásicos:
![]()
Figura 1: Diagramas de frecuencias clásicos. El tipo de la variable condiciona qué tipo de diagrama es válido. - A continuación, vemos los diferentes tipos de diagrama de frecuencias en función de la métrica de la variable

4.1 Diagramas para variables nominales, ordinales y discretas
Diagramas clásicos: el diagrama de sectores

- Principio gráfico: el ángulo del sector de cada clase es proporcional a su frecuencia: \(\small \alpha_i=360º\times p_i\) (figura A).
- Solo es válido para variables nominales (en un diagrama de sectores, si se respeta el orden, hay un punto en el que se pasa de la última categoría a la primera).
- Están en desuso:
- Ocupan mucho (el doble que un diagrama de barras) y dicen poco (a la vista le cuesta comparar ángulos).
- Las etiquetas rompen la lectura visual.
- La falsa tridimensionalidad induce a engaño (el diagrama B no cumple el principio gráfico antes citado) .
Evitar incluir diagramas de sectores en un informe siempre que sea posible.
En su lugar, son preferibles los diagramas de barras.
4.1.1 El diagrama de barras

- Principio gráfico:
- Cada categoría se representa con una barra separada de las demás.
- La altura de la barra es proporcional a la frecuencia (la absoluta, \(\small n_i\), o la relativa \(\small p_i\)).
- La comparación entre categorías es visualmente sencilla.
- Es el diagrama más apropiado para variables de tipo nominal, ordinal y discreto.
… El diagrama de barras

4.2 Diagramas para variables continuas (o discretas que lo parecen)
4.2.1 El histograma

- Es un tipo de diagrama adecuado para variables continuas y discretas agrupadas en intervalos (con corrección por continuidad, cpc).
- Principio gráfico:
- Los valores de la variable se agrupan en intervalos formando clases, a cada clase se asigna un rectángulo.
- El área del rectángulo debe ser proporcional a la frecuencia de la clase (\(n_i\) o \(p_i\)).
- Si los intervalos son homogéneos, que deben serlo, basta con que la altura del rectángulo sea proporcional a la frecuencia de la clase.
- A diferencia del diagrama de barras, ahora no hay separación entre rectángulos (continuidad de la variable).
- Dependiendo del tipo de frecuencias empleadas, el área total del histograma es aproximadamente \(n\), si se usan frecuencias absolutas, y aproximadamente \(1\) si se emplean frecuencias relativas. Esta normalización del área es lo que da lugar al concepto de densidad.
… El histograma

… El histograma

4.2.2 Curva de densidad estimada (KDE) y función de distribución acumulada empírica (ECDF)

- La curva KDE (Kernel Density Estimation) es una representación suave y continua de la distribución de los datos.
- Puede interpretarse como un histograma suavizado, en el que las barras se sustituyen por una curva que estima la densidad de probabilidad de la variable.
- A diferencia del histograma, que agrupa los datos en intervalos y depende de la elección de clases, la curva KDE asigna una densidad a cada observación y las combina, dando lugar a una curva continua cuya área total es 1.
- Este diagrama permite visualizar la forma de la distribución subyacente de manera más suave y menos dependiente de decisiones arbitrarias, manteniendo la interpretación en términos de densidad.
- Si se utilizan las frecuencias acumuladas, se obtiene la curva de distribución acumulada empírica (ECDF)
… Curva de densidad estimada (KDE) y función de distribución acumulada empírica (ECDF){#sec-KDE}
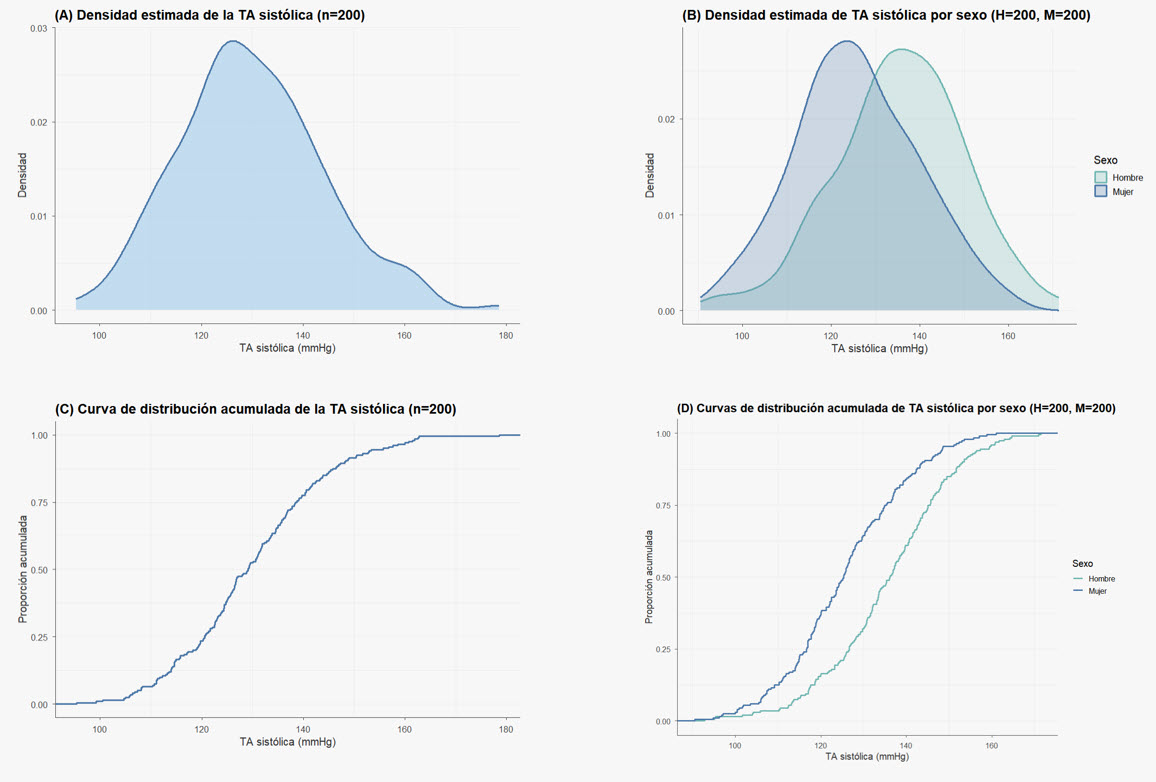
Las curvas acumulativas ECDF facilitan la lectura directa de los percentiles.
El uso de estas curvas resulta especialmente útil para comparar distribuciones: si una curva KDE aparece desplazada hacia la izquierda respecto a otra, la ECDF correspondiente tenderá a situarse por encima, lo que indica que, en general, los valores del primer grupo son menores que los del segundo.
4.2.3 Diagramas de caja (Boxplot)

- En un diagrama de caja (A, izda.), la línea central de la caja representa a la mediana y las líneas inferior y superior al primer y tercer cuartil respectivamente (ver la sección dedicada a los cuartiles). Las líneas exteriores se prolongan hasta la observación más próxima a \(\small W_1=Q_1-1.5\times RIQ\) la inferior, y \(\small W_2=Q_3+1.5\times RIQ\) la superior.
- Son diagramas robustos, muy útiles para detectar valores extremos.
- A menudo se complementan con la superposición de otro tipo de diagrama, por ejemplo de puntos (C) o curvas KDE (D)
4.2.4 Otros diagramas

5 Medidas descriptivas

¿Cómo se pueden caracterizar las semejanzas y diferencias de estas distribuciones?
Preguntas que interesa responder de manera objetiva:
- ¿Cuál es el valor “típico” o representativo de la distribución?
- ¿En qué punto de la distribución se sitúa un paciente de interés?
- ¿Son los pacientes muy homogéneos, o hay una gran dispersión entre ellos?
- ¿Cómo es la estructura global de la distribución?. Por ejemplo, ¿es simétrica?
Topografiando las distribuciones: leyendo sus puntos clave.

 CC-BY-ND
CC-BY-ND
Respondiendo a las preguntas: tipos de medidas descriptivas
- ¿Cuál es el valor “típico” o representativo de la distribución? → Medidas de posición central
- ¿En qué punto de la distribución se sitúa un paciente de interés? → Medidas de posición no central
- ¿Son los pacientes muy homogéneos, o hay una gran dispersión entre ellos? → Medidas de dispersión
- ¿Cómo es la estructura global de la distribución?. Por ejemplo, ¿es simétrica? → Medidas de forma
5.1 Medidas de posición
5.1.1 Medidas de posición central
- Pregunta a la que responden las medidas de posición central: ¿Cuál es el valor típico o representativo de la distribución?
- Hay diferentes criterios para dar respuesta a esta pregunta
¿Cuál es el valor más frecuente?
Moda
Definición: La moda (\(\small Mo\)) es la categoría, o el valor, de la variable cuya frecuencia es mayor.
- Cuándo tiene sentido:
- En variables cualitativas (nominales u ordinales) o discretas con recorrido limitado. De poco interés en variables continuas.
- Distribuciones con picos clínicamente relevantes.
- Ventajas: su interpretación es muy intuitiva, puede ser de interés para caracterizar grupos de pacientes.
- Limitaciones:
- Puede no existir, o no ser única.
- No es operativa algebraicamente.
- Apenas se utiliza en inferencia.
Ejemplo clínico: En un servicio hospitalario, el grupo sanguíneo más frecuente suele ser el O+. Identificar esta categoría modal es esencial para la planificación transfusional, la gestión del banco de sangre y la previsión de necesidades de hemoderivados.
![]() Cálculo: En el lenguaje base de R no hay ninguna función que devuelva el valor de la moda.
Cálculo: En el lenguaje base de R no hay ninguna función que devuelva el valor de la moda.
¿Cuál es el punto que divide la muestra en dos mitades?
Mediana
Definición: la mediana (\(\small Me\)) es el valor de la variable que divide a la muestra ordenada en dos partes iguales. Formalmente:
\[ Me=x_{\left(\frac{n+1}{2}\right)} \]
siendo \(\small x_{\left(j\right)}\) el valor de la variable que ocupa la posición \(\small j\) en la muestra ordenada (el paréntesis del subíndice indica “muestra ordenada”).
A la vista de una tabla de distribución de frecuencias, la mediana es el primer valor de la variable cuya frecuencia relativa acumulada es mayor o igual al 50% \((\small P_i \ge 0.5)\)
- Cuándo es útil:
- Como medida de posición central de variables de tipo ordinal.
- Cuando la variable es cuantitativa, la mediana es una buena medida de posición central
- Cuando la distribución es asimétrica
- Cuando aparecen valores extremos.
- Ventajas: es una medida robusta\(^{*}\), estable frente a la presencia de valores extremos.
- Limitaciones:
- Menos eficiente\(^{*}\) que la media cuando la distribución es simétrica.
- Difícil de manejar algebraicamente.
* Vemos más adelante los conceptos de robustez y de eficiencia.
Ejemplo: Los tiempos de espera en los servicios de urgencias presentan una distribución claramente asimétrica: muchos pacientes son atendidos en menos de una hora (mediana \(\approx\) 50 min), mientras que un grupo pequeño espera varias horas. Esta asimetría se debe a la variabilidad en la gravedad, picos de demanda, limitación de recursos, circuitos clínicos diferentes y pacientes pendientes de cama.
![]() Cálculo: para el vector
Cálculo: para el vector x: median(x) o quantile(x, 0.5)
¿Cuál es el valor promedio?
Media aritmética
Definición: La media aritmética es el valor obtenido al sumar todos los valores de una variable y dividir el resultado por el número de sumandos:
\[\bar{x}=\frac{\sum{x_i}}{n}\]
Es la medida de posición central más relevante (la que más vamos a usar en inferencia).
El concepto de media es más general. Además de la media aritmética, hay otros tipos de media.
¿Cuándo representa mejor a la distribución?
- Cuando la distribución es simétrica.
- Cuando no hay valores extremos aislados.
Ventajas: es una medida muy intuitiva y manejable algebraicamente (gran parte de la inferencia estadística se hace basada en las medias).
Limitaciones:
- Requiere que la variable sea cuantitativa.
- Puede ser muy sensible a valores extremos, especialmente si la muestra es pequeña.
Ejemplo: El nivel medio de la presión arterial sistólica en población adulta sana (sin patología cardiovascular) es de 120 mmHg.
![]() Cálculo: para el vector
Cálculo: para el vector x: mean(x).
5.1.2 Medidas de posición no central
¿Qué valor de la variable deja por debajo al \(p\,\)% de la distribución?
Cuantiles
El cuantil \(\small p\), en donde \(\small p\) indica un porcentaje, es el valor de la variable que en la muestra ordenada acumula por debajo al \(p\,\)% de las observaciones, y deja por encima al \(\small (100-p)\,\)% restante:
\[ C_{p}=x_{\left((n+1)\times\frac{p}{100}\right)} \]
siendo \(\small x_{\left(j\right)}\) el valor de la variable que ocupa la posición \(\small j\) en la muestra ordenada (recordemos que el paréntesis del subíndice indica “muestra ordenada”)
A la vista de una tabla de distribución de frecuencias, el cuantil \(C_p\) es el primer valor de la variable cuya frecuencia relativa acumulada es \(\small P_i \left(\times 100\right) \ge p\,\)%
Cuándo se puede determinar:
- Variables ordinales (son medidas de orden) o cuantitativas ← es necesario poder ordenar los valores.
- Muestras con un tamaño aceptable (en general, \(\small n \ge 30-100\)) ← Estas medidas no tienen sentido con muestras demasiado pequeñas.
Ventajas:
- Son medidas robustas frente a valores extremos.
- Permiten caracterizar los extremos de la distribución de forma robusta.
- Permiten interpretar el valor de una observación en el contexto de su distribución.
- Son medidas robustas frente a valores extremos.
Limitaciones:
- En muestras pequeñas (\(\small n<30\)) pueden carecer de sentido, no resultan medidas recomendables por ser inestables y poco representativas. En general, se recomienda que sea \(\small n \ge 30\), o preferiblemente, \(\small n \ge 100\).
Hay ciertos cuantiles que reciben nombre propio: los percentiles, deciles, terciles,cuartiles y la mediana son todos cuantiles.
Ejemplo: Decir que, en una muestra, el cuantil 75 del nivel de colesterol es
\[ C_{75}=210 \,\,\text{mg/dL} \]
indica que el 75% de las observaciones tienen 210 mg/dL o menos, mientras que el 25% restante tienen 210 mg/dL o más.
![]() Cálculo: para el vector
Cálculo: para el vector x y una proporción p, el cuantil \(\small C_p\) se obtiene como: quantile(x, p)
- Cuantiles con nombre propio:
¿Qué valores de la variable van acumulando un 1% de la distribución?
Percentiles
Los percentiles son los cuantiles \(\small C_1,\dots, C_{99}\). Hay un total de 99 percentiles: \(\small P_1,\dots, P_{99}\), que en conjunto dividen a la muestra en 100 partes, cada una con un 1% de las observaciones aproximadamente.
A la vista de una tabla de distribución de frecuencias, el percentil \(\small P_p\) es el primer valor de la variable cuya frecuencia relativa acumulada es \(\small P_i (\times 100)\ge p\,\)%
En Ciencias de la Salud es frecuente que se use el término percentil como sustituto de cuantil, pudiendo hablar así del percentil 2.5. Esto está ampliamente aceptado.
Observemos que \(\small Me=P_{50}\)
Ejemplo: Control de crecimiento infantil en consulta de Pediatría: Según las tablas de crecimiento infantil de la OMS, construidas con la información de miles de niños, un niño de 12 meses con un peso de 10.2 kg, se sitúa en el \(\small P_{75}\) de la distribución del peso de los niños con esta edad. Es decir, el 75% de los niños de 12 meses pesa 10.2 kg o menos. Esta información permiten localizar el peso de este niño en la distribución de referencia.
![]() Cálculo: para el vector
Cálculo: para el vector x, los percentiles son quantile(x, 0.01),…,quantile(x, 0.99)
¿Con qué criterio puedo dividir las observaciones en tres grupos del mismo tamaño?
Terciles
Los terciles son los cuantiles \(\small T_1=C_{33.3}\) y \(\small T_2=C_{66.6}\). Los dos terciles permiten dividir a la muestra en tres grupos, cada uno con 1/3 de las observaciones.
Ejemplo: En la consulta de Enfermería de Atención Primaria se evalúa la adherencia de los pacientes al tratamiento antihipertensivo mediante la escala Morisky-Green. La distribución de la adherencia suele ser heterogénea, de modo que interesa clasificar a los pacientes en grupos de adherencia baja, intermedia y alta. Esto permite dirigir intervenciones educativas sobre el control tensional según las necesidades. Así, el tercil inferior recibe estrategias intensivas, el intermedio un refuerzo específico y el superior un plan de mantenimiento. La división por terciles se presenta así como un recurso práctico para adaptar la atención con un criterio basado en los datos.
Observación: en el ejemplo se habla de tercil inferior para aludir al primer grupo generado por la división hecha con el \(\small T_1\). Este uso del lenguaje es común y aceptado; formalmente los terciles son dos valores, los grupos que se generan cortando con estos dos valores son tres.
![]() Cálculo: para un vector de datos
Cálculo: para un vector de datos x, los dos terciles son quantile(x, 0.333) y quantile(x, 0.666)
¿Con qué criterio puedo dividir las observaciones en cuatro grupos del mismo tamaño?
Cuartiles
Los cuartiles son los cuantiles \(\small Q_1=C_{25}\), \(\small Q_2=C_{50}\) y \(\small Q_3=C_{75}\). Los tres cuartiles permiten dividir a la muestra en cuatro grupos, cada uno con 25% de las observaciones.
- La mediana es el segundo cuartil: \(\small Me=Q_2\)
- La caja de los diagramas de caja se construye tomando como base de la caja al primer cuartil y como techo el tercer cuartil. La línea central representa la posición del segundo cuartil, es decir, de la mediana.
Ejemplo En una unidad de hospitalización se registra diariamente el nivel de dolor postoperatorio mediante una escala visual analógica (EVA) en los pacientes intervenidos de cirugía abdominal. Dado que los valores de dolor suelen presentar gran variabilidad y una distribución irregular, dividir la muestra en cuartiles permite identificar cuatro perfiles de pacientes según su intensidad de dolor. El primer cuartil agrupa al 25% de pacientes con dolor más bajo, mientras que el cuarto cuartil identifica al 25% con mayor dolor persistente, que pueden requerir revisión del plan analgésico, técnicas no farmacológicas adicionales o una valoración más estrecha. Esta clasificación en cuartiles facilita priorizar la intervención enfermera y ajustar los cuidados según la intensidad real del dolor.
Como ya pasó en el ejemplo de los terciles, en este también se habla de forma indistinta para aludir al cuartil como medida -es lo correcto- y a cada uno de los grupos que genera la división con los tres cuartiles. Aunque esta doble interpretación no es estrictamente correcta desde un punto de vista formal, es un uso habitual y ampliamente aceptado en la práctica.
En el ranking de impacto de las revistas científicas, se habla de revistas del primer cuartil para aludir a aquellas que ocupan el 25% de los primeros puestos respecto al orden del total de las revistas del área.
![]() Cálculo: para el vector
Cálculo: para el vector x, los tres cuartiles son quantile(x, 0.25), quantile(x, 0.50) y quantile(x, 0.75)
Hay más, como los quintiles (los cuatro valores que, conjuntamente, dividen a la distribución en 5 partes iguales), los deciles (los nueve valores que dividen a la distribución en 10 partes iguales), etc. Se pueden considerar todas las divisiones que resulten convenientes, en el fondo, todos son cuantiles
5.2 Medidas de dispersión

CC-BY-ND
¿Cómo se puede caracterizar la variabilidad de estas distribuciones?
- Las medidas de dispersión describen cuánto varían los datos
- Normalmente para medir cuánto varían los datos se considera un punto de referencia: una medida de posición.
- Permiten entender si los valores están agrupados, muy dispersos o si existen grandes diferencias internas en la distribución.
5.2 Medidas de dispersión
¿En cuántas unidades (métricas) se reparte toda la distribución?
Rango o Amplitud
El rango, o amplitud, es la diferencia entre los valores máximo y mínimo de la distribución:
\[Rango = Máximo – Mínimo\]
- Ventajas
- Es muy fácil de calcular y resulta muy intuitivo.
- Es útil para detección rápida de valores extremos.
- Limitaciones
- Solo depende de dos valores, el resto de la muestra no aporta más información.
- Es extremadamente [sensible]{-neg} a los valores extremos.
- Su uso en inferencia no suele ir más allá de su valor intuitivo.
- Solo depende de dos valores, el resto de la muestra no aporta más información.
x, el rango es rango <- max(x)-min(x)
- Medidas basadas en la media como medida de posición
¿Cuánto se alejan los datos de la posición central?
Varianza

Una idea es obtener el promedio de las distancias de cada observación a una medida de posición central, por ejemplo \(\small \bar{x}.\)
Estas distancias son \(\small d_i=x_i-\bar{x}\), pero debido al criterio de centralidad de \(\small \bar{x}\), siempre resulta \(\small \sum{d_i}=0\).
La solución es evitar que haya distancias negativas haciendo el promedio con \(\small d_i^2\)
La varianza (\(s^2\)) es el promedio de las desviaciones – elevadas al cuadrado– de las observaciones respecto a la media aritmética:
\[ \displaystyle s^2= \frac{\sum{d_i^2}}{n-1} = \frac{\sum{\left(x_i-\bar{x}\right)^2}}{n-1} \]
- Es un indicador de cuánto se alejan, en promedio, los datos observados del valor central.
- En este promedio, no se usa como denominador el tamaño muestral \(\small n\), sino los grados de libertad \(\small (n-1)\), que representan la cantidad de información realmente independiente disponible en una muestra: al calcular la varianza, ya hemos utilizado la información muestral para calcular la media.
- Ventajas
- Es la medida de variabilidad más importante, presente prácticamente en la gran mayoría de las técnicas estadísticas inferenciales.
- Aprovecha toda la información de la muestra, ya que considera la totalidad de las observaciones.
- Es la medida de variabilidad más importante, presente prácticamente en la gran mayoría de las técnicas estadísticas inferenciales.
- Limitaciones
- Es difícil de interpretar, ya que está expresada en las unidades de la variable al cuadrado.
Por ejemplo, si evaluamos la altura de los pacientes en metros, la varianza quedará expresada en metros cuadrados, que es una unidad de superficie, no de longitud.
- Es difícil de interpretar, ya que está expresada en las unidades de la variable al cuadrado.
Ejemplo: En el control de la presión arterial sistólica en pacientes con hipertensión, la varianza tiene una relevancia clínica directa. Dos tratamientos pueden lograr la misma media (por ejemplo, 130 mmHg), pero si uno presenta una varianza baja —con valores muy próximos a la media— y el otro una varianza alta —con oscilaciones amplias entre mediciones—, el primero refleja un control hemodinámico más estable y predecible que el segundo. Así, la varianza no solo cuantifica la dispersión estadística, sino que también mide la estabilidad clínica y el posible riesgo cardiovascular asociado a la variabilidad.
![]() Cálculo: para un vector
Cálculo: para un vector x, su varianza es var(x)
¿Cuánto se alejan los datos de un valor central, en las mismas unidades de la media?
Desviación típica o desviación estándar
La desviación típica (\(s\)) o desviación estándar es la raíz cuadrada de la varianza.
\[ \displaystyle s = \sqrt{\frac{\sum{\left(x_i-\bar{x}\right)^2}}{n-1}} \]
- Ventajas
- Como hace la varianza, aprovecha la información de todos los datos.
- Expresa la variabilidad en las mismas unidades que la media, por lo que son cantidades que se pueden sumar y restar. Como veremos, la media y la desviación típica van a ser compañeras inseparables.
- Si la distribución es simétrica, es una medida fácil de interpretar cuando acompaña a la media aritmética.
- La desviación típica es la medida de dispersión más usada en investigación clínica y epidemiología.
- Limitaciones. Al igual que la media aritmética, la desviación típica:
- Puede resultar sensible a la presencia de valores extremos, especialmente si el tamaño muestral es reducido.
- Puede resultar menos informativa y poco adecuada cuando la distribución es muy asimétrica.
- Puede resultar sensible a la presencia de valores extremos, especialmente si el tamaño muestral es reducido.
Ejemplo clínico: En el seguimiento de la presión arterial sistólica en pacientes con hipertensión, la desviación típica permite interpretar de forma directa la variabilidad clínica. Mientras que la varianza expresa la dispersión en unidades al cuadrado (mmHg²) y resulta útil desde el punto de vista matemático e inferencial, la desviación típica se expresa en las mismas unidades que la variable original (mmHg), lo que facilita su interpretación clínica.
![]() Cálculo: para un vector
Cálculo: para un vector x, su desviación estándar es sd(x)
Dadas dos distribuciones, ¿cuál presenta mayor variabilidad relativa respecto a su media?
Coeficiente de variación (CV)
El coeficiente de variación \(\small (CV)\) es la relación entre la desviación típica y la media. Habitualmente, su valor se multiplica por 100 y se expresa como porcentaje:
\[ \displaystyle CV= \frac{s}{\bar{x}}\,\,\left(\times100\%\right) \]
- Ventajas
- Permite comparar la dispersión entre distribuciones con medias diferentes.
- También es adecuado para comparar la variabilidad de variables con distintas unidades.
- Muy útil como medida relativa de dispersión cuando la media es positiva y estable.
- Limitaciones
- No debe usarse cuando la media es pequeña, próxima a 0 (en general, se debe evitar el cálculo de este coeficiente si \(\small \bar{x}<1\)).
- Puede ser engañoso en distribuciones muy asimétricas, donde la desviación típica y la media pierden representatividad.
- No debe usarse cuando la media es pequeña, próxima a 0 (en general, se debe evitar el cálculo de este coeficiente si \(\small \bar{x}<1\)).
Ejemplo: En el control de la diabetes, el coeficiente de variación (CV)se utiliza para valorar la estabilidad de la glucemia a lo largo del día. No basta con conocer la media: un CV elevado indica que las cifras de glucosa oscilan demasiado en relación con su valor medio, lo que se asocia a mayor riesgo de hipoglucemias y descompensación metabólica. Por eso, en práctica clínica se considera que un CV glucémico superior al 36% refleja una variabilidad excesiva y la necesidad de revisar ajustes terapéuticos, los hábitos cotidianos o incidir en la educación diabetológica.
- ¿Podríamos comparar la variabilidad de la glucemia (mg/dL) frente a la variabilidad de la frecuencia cardíaca (lpm)? Son variables con diferentes unidades. Pero si esta comparación tuviera sentido clínico, es viable hacerla a través del CV.
El coeficiente de variación es una medida muy útil cuando queremos valorar la precisión de un instrumento de medida. Mientras que la desviación típica dice cuánta variabilidad absoluta hay entre repeticiones de una medida, el CV expresa esa variabilidad en proporción al valor medio, lo que permite comparar la fiabilidad de aparatos distintos o que midan escalas diferentes.
![]() Cálculo: no hay una función que proporcione el CV directamente. Para un vector
Cálculo: no hay una función que proporcione el CV directamente. Para un vector x una función personalizada que devuelve el CV cuando es lícito su cálculo es:
Más…
- Medidas basadas en la mediana como medida de posición
¿En cuántas unidades se dispersa la mitad central de la distribución?
Rango intercuartílico (RIQ)
El rango intercuartílico \((\small RIQ)\) es la diferencia entre el tercer y el primer cuartil:
\[ \displaystyle RIQ = Q_3 – Q_1 \]
- Describe la variabilidad del 50% central de los datos.
- También se abrevia como RIC y, en inglés, como IQR.
- A menudo, en los informes, en lugar de indicar el RIQ como diferencia, se indican sus componentes: \(\small Q_1\)-\(\small Q_3\)
- Ventajas
- Es fácil de interpretar.
- Es una medida robusta ante valores extremos.
- Es la medida de dispersión preferible para caracterizar distribuciones asimétricas.
- Limitaciones
- No utiliza toda la información de la muestra.
- Como ocurre con los cuantiles, requiere que el tamaño de muestra sea suficientemente grande (\(\small n>30\), o mejor, \(\small n>100\)).
- No utiliza toda la información de la muestra.
Ejemplo: En tiempos de estancia hospitalaria, un RIQ amplio indica diferencias marcadas en los días que permanecen los pacientes ingresados, incluso si la media no es extrema. Concretamente, si el primer cuartil es de 3 días y el tercer cuartil es de 11 días, el rango intercuartílico es de 8 días, lo que indica que el 50 % central de los pacientes permanece ingresado entre 3 y 11 días. Una diferencia de 8 días sugiere una elevada variabilidad clínica en la duración de las estancias hospitalarias.
![]() Cálculo: para un vector
Cálculo: para un vector x, su RIQ es IQR(x)
¿Hay más rangos de interés?
Otros rangos
El Rango semi-intercuartílico (RSIQ), que se define como
\[ \displaystyle RSIQ=\frac{RIQ}{2} \]
- El RSIQ mide la variabilidad del 50 % central de los datos mediante una escala más compacta.
Puede interpretarse como una dispersión “típica” alrededor de la mediana, de forma análoga a cómo la desviación típica describe la dispersión respecto a la media aritmética. - Resulta útil cuando se desea una medida de variabilidad robusta y poco sensible a valores extremos, pero más sencilla de interpretar que el RIQ.
- Mientras que el RIQ representa la anchura de la zona central de la distribución, el RSIQ expresa una distancia típica respecto al centro.
Ejemplo: En una unidad de cirugía, los registros de dolor suelen mostrar valores muy extremos en algunos pacientes (picos en la escala EVA de 9–10), si el RSIQ=2, la mitad central de los pacientes se aparta, aproximadamente, \(\small \pm\) 2 puntos respecto del valor mediano. Esto permite valorar la estabilidad del control del dolor, comparar turnos o procedimientos y detectar cuándo la variabilidad aumenta sin que los valores atípicos distorsionen el análisis.
En la práctica, se pueden definir rangos a partir de cualquier pareja de cuantiles.
Por ejemplo los rangos P5-P95 \(\small =P_{95}-P_{5}\) o P10-P90 = \(\small P_{90}-P_{10}\) se han usado en el análisis de la función pulmonar (Roberts, 2010) y en estudios sobre neonatología y pediatría (Tao, 2025), respectivamente.
6 Algunas consideraciones sobre las medidas descriptivas
- Síntesis descriptiva en trabajos de investigación
Síntesis de las variables cualitativas
- En un informe, las variables cualitativas se resumen indicando las frecuencias (absolutas y relativas) correspondientes a cada categoría. Este es un ejemplo:

- Algunos conceptos importantes:
Concepto de estadístico
Un estadístico es cualquier función obtenida a partir de los datos de una muestra y que resume alguna característica de esos datos.
- El estadístico solo depende de los datos muestrales (su determinación no requiere de información adicional).
- Todas las medidas descriptivas de este capítulo son estadísticos.
- El concepto de estadístico es especialmente importante en inferencia.
Robustez y eficiencia de un estadístico
La robustez es la resistencia de un estadístico frente a la presencia de valores extremos. Cuanto más robusto es un estadístico, menos se altera cuando aparecen datos anómalos.
La eficiencia es la capacidad de un estadístico para presentar poca variabilidad cuando repetimos el muestreo en las mismas condiciones. Un estadístico eficiente fluctúa muy poco entre muestras.
6.1 Variables cuantitativas: ¿qué usar la media o la mediana?

6.1 Variables cuantitativas: ¿qué usar la media o la mediana?

- Criterios comparativos
Manejo de la información
- La media aprovecha toda la información cuantitativa de los datos: tiene en cuenta las distancias entre los valores.
- La mediana usa únicamente el orden de los datos: no depende de las distancias.
Criterio de centralidad
- La media es el punto de equilibrio de la distribución: la suma de las distancias (con signo) de los valores inferiores y superiores se iguala:
\[ -\sum_{x_i<\bar{x}}{\left(x_i-\bar{x}\right)} = \sum_{x_i>\bar{x}}{\left(x_i-\bar{x}\right)} \]
- La mediana es simplemente el valor que deja la mitad de las observaciones a cada lado.
Eficiencia
- Si tomamos muchas muestras distintas de la misma población, las medias muestrales fluctúan menos que las medianas muestrales en distribuciones simétricas: la media es estadísticamente más eficiente.
Robustez
- La media es sensible a valores extremos (outliers): un solo valor extremo puede provocar un cambio grande.
- La mediana es una medida más robusta: los valores anómalos apenas la afectan (haría falta cambiar al 50% de los datos).
- Esta diferencia es especialmente relevante en muestras pequeñas. A medida que aumenta el tamaño muestral, la media se vuelve más estable, es decir, el efecto relativo del valor extremo es menor.

Interés en inferencia
- La media aritmética es el valor que minimiza la suma de las distancias cuadráticas respecto a los datos; este es un criterio óptimo de estimación en muchos modelos inferenciales.
6.1 Variables cuantitativas: ¿qué usar la media o la mediana?
¿Media o mediana? Resumen
En distribuciones simétricas, la media es la medida de posición central más eficiente: utiliza mejor la información cuantitativa y varía menos entre muestras tomadas en las mismas condiciones y de la misma población.
En distribuciones asimétricas o con valores extremos, la mediana es más robusta y describe mejor el “centro” de la distribución, especialmente cuando el tamaño muestral es reducido, situación en la que la media resulta más sensible.
Sin embargo, cuando el tamaño muestral es grande, el impacto relativo de un valor extremo sobre la media disminuye y este estadístico se vuelve más estable. En inferencia vamos a usar preferentemente la media como medida de posición central.
Media y desviación típica
La pareja “media (desviación típica)” (evitar el uso de la notación “media \(\pm\) desviación típica”) debe de ir siempre junta y es muy informativa cuando la distribución es simétrica.
Si la distribución es simétrica con forma de campana (más adelante llamaremos normal a una distribución con estas características), en el intervalo
\[ \left(\bar{x} - 2 \times s,\,\,\bar{x}+ 2 \times s\right) \]
se concentran, aproximadamente, el 95% central de las observaciones. Es decir, en estas condiciones
\[ P_{2.5} \approx \bar{x}-2 \times s\space\space\space \text{y} \space \space\space P_{97.5} \approx \bar{x}+2 \times s. \]

Mediana y RIQ
Cuando se utiliza como medida de posición central la mediana, la medida de dispersión que la acompaña es el RIQ o el RSIQ. Pero cuidado con su interpretación; si la distribución es asimétrica, la mediana no está a la misma distancia de cada cuartil.
Ejemplos
| Situación clínica | Distribución | Medidas recomendadas: posición (dispersión) | Justificación de la medida de posición |
|---|---|---|---|
| Presión arterial en población sana | Aproximadamente normal | Media (desv. típica) | Representa bien el centro de la distribución |
| Tiempos de espera en urgencias | Muy asimétrica | Mediana (RIQ o RSI) | Evita la distorsión causada por esperas largas |
| Frecuencia cardiaca sin arritmias | Simétrica | Media (desv. típica) | Estabilidad fisiológica entre pacientes |
| Reconsultas en Atención Primaria | Cola larga por hiperfrecuentadores | Mediana (RIQ o RSI) | Robustez ante valores extremos |
| Glucemia en diabéticos controlados | Casi normal | Media (desv. típica) | Población homogénea |
| Temperatura corporal | Simétrica, sin valores extremos | Media (desv. típica) | Gran homogeneidad y baja variabilidad |
| Estancia hospitalaria | Cola larga | Mediana (RIQ o RSI) | Reduce el impacto de estancias muy prolongadas |
| EVA de dolor | Irregular, extremos frecuentes | Mediana (RIQ o RSI) | Mejor representación del valor típico |

 .
.