Tema 1
Introducción
22/mayo/2026
1 Necesidad de la Estadística en Ciencias de la Salud
\(\tiny \blacksquare \,\,\) Las Ciencias de la Salud (CCS) se centran en el estudio, la promoción y la protección de la salud humana, tanto individual como colectiva.
\(\tiny \blacksquare \,\,\) La información que permite llevar a cabo este desempeño es de naturaleza cuantitativa (prevalencias, niveles de sustancias en sangre, escalas de valoración,…) y se presenta impregnada de una gran variabilidad.
Diversidad humana: la variabilidad es fuente de complejidad

¿Cuál de las dos es más dificil de describir? ¿por qué?
\(\tiny \blacksquare \,\,\) En este contexto, la Estadística se presenta como una herramienta fundamental, ya que permite:
- Diseñar y planificar investigaciones (como ensayos clínicos o estudios epidemiológicos) de forma válida y eficiente.
- Analizar e interpretar objetivamente datos de pacientes, poblaciones o experimentos para obtener conclusiones objetivas y fiables.
- Evaluar la eficacia y seguridad de tratamientos, medicamentos o intervenciones sanitarias.
- Tomar decisiones basadas en evidencia, reduciendo la incertidumbre y el error.
- Comunicar resultados científicos de manera objetiva y comprensible.
\(\tiny \blacksquare \,\,\) Florence Nightingale: enfermera, reformadora, estadística, administradora, investigadora.
\(\tiny \blacksquare \,\,\) En palabras de la OMS:En todos los dominios de las Ciencias de la Salud, en su vertiente clínica, administrativa o de la investigación, es indispensable conocer los principios estadísticos para comprender bien los problemas y el profesional de la Salud necesita de los datos estadísticos para tomar decisiones válidas 1
1 Martín Andrés & Luna del Castillo (2004, p. 4)
2 Primeras definiciones
\(\tiny \blacksquare \,\,\) Población es el conjunto de sujetos o de elementos de interés en un estudio.
\(\tiny \blacksquare \,\,\) Entenderemos por variable a una característica cuyo valor o modalidad puede cambiar entre los diferentes sujetos de la población
El primer paso para poder estudiar alguna particularidad de una población es recurrir a algún tipo de resumen que la caracterize.
\(\tiny \blacksquare \,\,\) Un parámetro poblacional es un resumen numérico de la población (en el contexto de la característica de interés).
\(\tiny \blacksquare \,\,\) Una muestra es un subconjunto de sujetos de una población.
Cuanto mayor es el tamaño de una muestra ¿es mayor su representatividad?

3 Qué es la Estadística
La Estadística es la ciencia que se encarga de desarrollar y aplicar métodos para la recolección, organización, análisis, interpretación y presentación de datos.
La inferencia estadística supone un razonamiento inductivo

\(\tiny \blacksquare \,\,\) Los aspectos fundamentales que cubre la Estadística son
- Diseño del estudio. Es la planificación de la toma de datos: cómo se obtienen, bajo qué condiciones y con qué estructura. Los dos grandes tipos de estudios son el observacional (el investigador solo observa) y el experimental (el investigador interviene asignando tratamientos o condiciones).
- Descripción. Síntesis, resumen de los datos obtenidos en la muestra.
-
Inferencia. Es la metodología que permite sacar conclusiones sobre una población a partir de los datos observados en una muestra. .
Consideraremos dos facetas de la inferencia - Teoría de la estimación Su objetivo es asignar valores a los parámetros poblacionales desconocidos (por ejemplo, conocer qué valor toma la prevalencia de una enfermedad en la población)
- Teoría de los contrastes de hipótesis Su objetivo es decidir si es aceptable o no una hipótesis estadística (por ejemplo, decidir si hay asociación entre el consumo de alcohol y el cáncer de esófago)
- Adicionalmente, la síntesis de los resultados obtenidos también debe hacerse bajo criterios estadísticos.
4.2 Tipos informáticos
\(\tiny \blacksquare \,\,\) Desde el punto de vista informático, el tipo, o la clase, de una variable alude a la forma como se almacena la información y las operaciones que resultan admisibles.
 Tipos básicos en R
Tipos básicos en R
| Tipo básico | Ejemplo | Descripción |
|---|---|---|
| numeric |
3.14, 2.0
|
Números reales (doble precisión por defecto) |
| integer |
2L, 10L
|
Números enteros (la “L” indica tipo entero) |
| logical |
TRUE, FALSE
|
Valores lógicos o booleanos |
| character |
"hola", "R"
|
Cadenas de texto |
| complex |
2 + 3i
|
Números complejos (sin interés aquí) |
| raw |
charToRaw("A")
|
Datos en formato binario (sin interés aquí, raro en el uso común) |
\(\tiny \blacksquare \,\,\) Además de los tipos básicos, en R se definen ciertas estructuras de datos, que constituyen una forma organizada de almacenar valores de los tipos básicos que determina cómo se accede, manipula y procesa la información.
Estructuras de datos
| Estructura | Homogénea o heterogénea | Descripción | Ejemplo |
|---|---|---|---|
| Vector | Homogénea | Conjunto de elementos del mismo tipo básico |
c(1, 2, 3)
|
| Matrix / Array | Homogénea | Vectores con 2 o más dimensiones |
matrix(c(1,2,3,4), nrow=2,byrow=TRUE)
|
| List | Heterogénea | Colección de [objetos.{cur}] de distintos tipos o estructuras |
list(1, "a", TRUE)
|
| Data frame | Heterogénea por columnas | Lista especial en donde cada elemento columna es un vector de la misma longitud. |
data.frame(x=c(1,2,3), y=c("a","b","c"))
|
| Factor | Especial (categórico) | Codifica variables cualitativas (texto) como enteros con etiquetas. |
factor(c("bajo", "alto", "medio"))
|
4.3 Tipos funcionales
\(\tiny \blacksquare \,\,\) Desde el punto de vista del rol que desempeñan las variables en un estudio, se puede hablar de
- Variables respuesta son aquellas cuyos niveles o valores se pretenden analizar en términos de los valores o los niveles de otras variables
- Variables explicativas son las variables cuyos niveles o valores pueden estar asociados o ser condicionantes de los que toma la variable respuesta
\(\tiny \blacksquare \,\,\) También se pueden distinguir
-
Variables mediadoras o moderadoras: Son aquellas que alteran la relación entre las variables explicativas y la respuesta.
En una relación causal, forman parte intermedia en el mecanismo entre la causa (variable explicativa) el efecto (variable respuesta) - Variables confusoras: Son aquellas que están asociadas tanto con la variable explicativa como con la respuesta y pueden distorsionar la relación observada entre estas últimas
- Variables extrañas: son aquellas que no se han considerado en la investigación y que pueden tener un efecto confusor en la relación entre las variables de interés (es importante identificarlas en la etapa de diseño e intentar controlarlas)
Relación entre el nivel de actividad física y la presión arterial sistólica

- Supuesto a investigar: La práctica de actividad física (AF) reduce la presión arterial sistólica (PAS)
- Mecanismo mediador: La AF reduce la frecuencia cardiaca en reposo, lo que a su vez contribuye a reducir la PAS
- Confusión: Valores más altos de la edad o del índice de masa corporal suelen reducir la práctica de AF y aumentar la PAS
5 Presentación de los datos
\(\tiny \blacksquare \,\,\) El análisis estadístico se realiza habitualmente sobre datos estructurados en forma de matriz de casos\(\times\)variables.
Se trata de una organización en forma de matriz bidimensional, con filas y columnas, en donde cada fila representa a un caso y cada columna a una variable.
Matriz de casos\(\times\)variables: el data.frame
Es una estructura rectangular en la que los datos de una misma columna son siempre del mismo tipo y los datos de columnas diferentes pueden tener tipos diferentes.
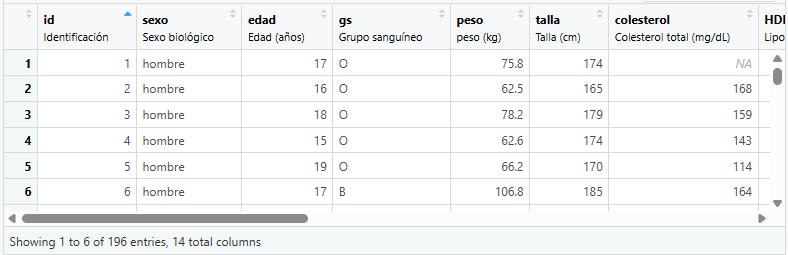
Cuando se desconoce la información de una variable para un caso concreto, se dice que se tiene un dato faltante o perdido.
Esto se codifica comoNA(del inglés Not Available).![]()
Presentación de un data.frame en RStudio. El primer sujeto presenta un valor faltante ( NA) en la variablecolesterol.

 .
.