2 Necesidad de la Estadística
Las Ciencias de la Salud pueden contemplarse como una disciplina especializada que está inmersa en un ámbito mucho más general, el de las Ciencias de la Vida, y si algo caracteriza a la vida es su enorme variabilidad1. Esta afecta a todos los niveles. Desde las múltiples modalidades en que se pueden presentar los organismos vivos, hasta la diversidad de individuos de una misma especie, o de células en un mismo organismo, o de moléculas que -teniendo la misma composición química- presentan estructuras tridimensionales diferentes. Sin duda, esta variabilidad confiere a nuestro mundo una gran dosis de complejidad, algo que lo hace mucho más interesante a la par que más difícil de conocer. Centrando la atención en nuestra especie, Richard Lewontin, en su ensayo La diversidad humana, define a esta como
la variedad de características personales específicas que hacen a cada ser humano único y diferente de los demás. […] Algunas de estas características son la edad, la clase social, el estatus socioeconómico, la corporalidad, el estado de salud, las capacidades y las aptitudes, el sexo, la orientación sexual, la identidad de género, la nacionalidad, el origen étnico, la cultura, la religión, la espiritualidad o las creencias. (lewontin1984?).

Podemos seguir indefinidamente añadiendo características a la relación señalada por Lewontin: el peso, la estatura, el nivel de colesterol, el nivel de glucemia, la calidad de vida, la autosuficiencia, etc. En algunos caracteres, la diversidad se deriva de la variabilidad genética. Sin embargo, los rasgos que quedan determinados geneticamente para toda la vida del sujeto son más la excepción que la norma. El grupo sanguíneo es un buen ejemplo de determinismo genético, se nace y se muere con el grupo que fue definido en la concepción del sujeto. Sin embargo, en la gran mayoría de los rasgos, la determinación genética se traduce en una correspondencia entre los ambientes posibles y un “paisaje” de fenotipos resultantes. Pero la interacción con el entorno introduce aún más variabilidad que la derivada de la “elección del paisaje”. A lo largo de su vida, cada sujeto está expuesto al ruido de desarrollo. Se trata de acontecimientos de naturaleza aleatoria que van a influir de forma decisiva en los rasgos que caracterizan al individuo. Esto pone de manifiesto la importancia del azar -como suceso accidental- y el hecho de que la dimensión temporal actúa promoviendo el aumento de complejidad. Por lo tanto, las peculiaridades de cada sujeto dependerán también del momento en sea observado.
(mcshea2010?) contemplan al tiempo como un generador de variabilidad hasta el punto de constituir per sé una fuerza evolutiva. A lo largo del tiempo, los factores aleatorios (accidentales, imprevisibles) que afectan a cualquier sistema inducen un aumento de su complejidad.
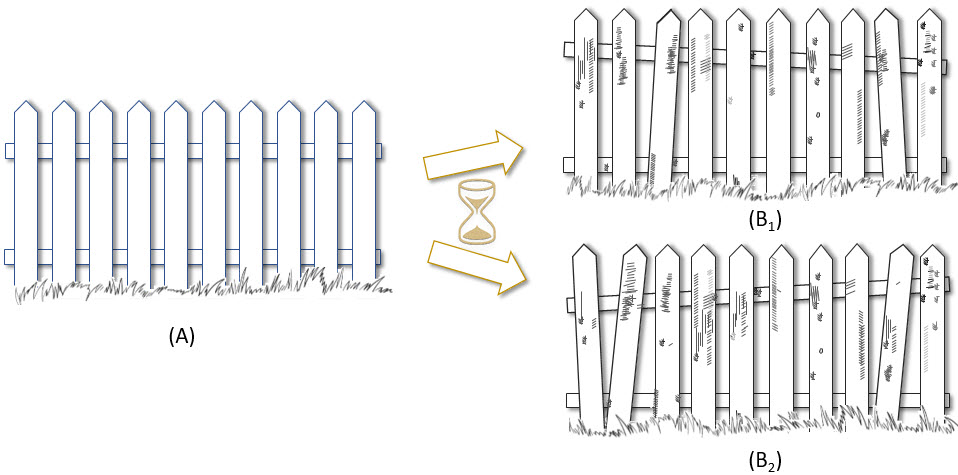
¿Cuál de las vallas de la figura se describe de forma más simple, la que está recién construida (A) o la misma valla transcurridos unos años (B1, o quizá B2)? La mayor variabilidad en los elementos que constituyen la segunda hace que su caracterización sea más difícil, más compleja, en comparación con la primera, donde los listones son idénticos. Por otra parte, ¿es admisible pensar que B1 y B2 son el mismo tipo de valla? No son exactamente iguales, pero ¿hasta qué punto se puede pensar que las diferencias no son relevantes?.
En este contexto, de enorme variabilidad, es en el que se desenvuelven las Ciencias de la Vida y, en particular, las Ciencias de la Salud. En él, la tarea de saber si, por ejemplo, determinado tratamiento es efectivo para curar cierta enfermedad, se complica. Hay sujetos para los que sí lo es y otros para los que no tanto. ¿Por qué? ¿Cuales son los factores que condicionan esta efectividad?
A esta dificultad, se une el hecho de que las poblaciones bajo estudio suelen ser de un tamaño tan grande que las hace inobservables en su totalidad. Por ejemplo, no es posible observar a toda la población con hipertensión para saber si es mejor administrar el tratamiento a primera hora del día o por la tarde, o si da igual. Es más, algunas personas de la población ni siquiera saben que son hipertensos. Por otra parte, las poblaciones son dinámicas, están en cambio permanente. Hay entrada y salida de sujetos así como cambios de estado. Si pudiéramos observar a todos los hipertensos, durante el proceso la población habrá cambiado.
La solución es que en lugar de investigar a toda la población, hay que conformarse con considerar a una parte de ella, una muestra. Aquí es donde nace la necesidad de la Estadística. Por un lado, la forma de obtener la muestra debe garantizar su representatividad. De ello se preocupan las técnicas de muestreo estadístico. Una vez obtenida la muestra, el siguiente paso es sintetizar la información que esta contiene mediante las técnicas descriptivas. Pero el resumen de los casos observados no suele ser de mayor interés si no es posible derivar, a partir de ellos, conclusiones para toda la población. Esto supone considerar razonamientos de tipo inductivo, es decir, procesos de pensamiento lógico que permitan llegar a conclusiones generales a partir de observaciones particulares. Según este tipo de razonamiento, la conclusión obtenida no es necesariamente cierta, será necesario considerar que se verifica con cierta probabilidad. Este proceso inductivo es llevado a cabo por los métodos inferenciales, cuyo pilar básico es la teoría de la probabilidad.
La aplicación del proceso descrito es el que actualmente permite avanzar en el conocimiento en el ámbito de las Ciencias de la Salud. Gracias a él, es posible identificar relaciones y tendencias en los datos clínicos, tomar decisiones basadas en la evidencia, evaluar la efectividad de un tratamiento, y un largo etcétera.
2.1 Conceptos básicos
Población. Normalmente, se entiende por población un conjunto de elementos de la misma naturaleza, claramente definido en el espacio y el tiempo, y que es objeto del estudio. Los elementos de la población pueden ser sujetos (como los habitantes de un país, o los individuos seropositivos de VIH, etc.) o cualquier otra entidad (hospitales, hogares, bacterias, etc.). Esta definición corresponde a poblaciones que son reales, tangibles. Sin embargo, a menudo conviene establecer escenarios definiendo poblaciones conceptuales, generadas por una abstracción. En cualquier caso, el concepto de población suele tener implícita la imposibilidad de poder observarla en su totalidad en un periodo de tiempo razonable. Se trata de conjuntos de gran tamaño2 y sometidos a un comportamiento dinámico, sus elementos están expuestos a cambios inducidos por el paso del tiempo. Adicionalmente, aunque la población sea tangible, es frecuente que presente elementos que resulten inaccesibles para su observación. Es por ello que se distingue la población de muestreo, aquella parte de la población original que sí es posible observar, de la población objetivo, aquella sobre la que va dirigido el estudio, siendo lo ideal que ambas coincidan.
Muestra. Dada la imposibilidad de observar a toda la población en su totalidad, el recurso científico es seleccionar un subconjunto de elementos de la misma que sí sea manejable, es decir, una muestra, que se conformar en un instante puntual o bien conforme a una dimensión temporal. Se habla de tamaño muestral (\(n\)) para aludir al número de elementos que componen la muestra. Si el tamaño poblacional (\(N\)) es conocido, entonces \(f=n/N\) es la fracción de muestreo. De manera similar a cuando se toma una fotografía para representar a un paisaje, la muestra debe ser representativa de la población a la que pertenece. Esta representatividad debe entenderse en el sentido de que en la muestra queda reflejada, en su justa medida, toda la variabilidad de caracteres que están presentes en la población. La representatividad de la muestra la garantiza la forma en que se seleccionan los elementos de la población para constituirla. Este proceso de selección resulta más fácil de hacer cuando cuando la población (de muestreo) tiene asociado un marco de muestreo, esto es, algún tipo de registro de los elementos de la población que posibilite la selección de los casos que van a componer la muestra. Una forma de selección que favorezca la presencia de ciertos caracteres y la ausencia de otros en el conjunto final da lugar a una muestra sesgada. El sesgo, o tendencia, se traduce en que las inferencias sobre la población serán erróneas. Por lo tanto, una muestra debe de ser insesgada para poder ser representativa de la población de la que se ha extraído. Más adelante, tras abordar las nociones básicas sobre probabilidad, se considerarán algunos aspectos del muestreo.
Parámetro. Un parámetro poblacional es una cantidad numérica que sintetiza cierta información relativa a la población. Por ejemplo, la prevalencia actual del tabaquismo en la población española, es un parámetro que caracteriza la extensión del consumo de tabaco en dicha población. La forma de determinar su valor es muy sencilla, basta con dividir el número actual de fumadores por el tamaño de la población, \(N\):
\[prevalencia \left( \text{tabaquismo} \right) = \frac{\text{nº de fumadores}}{N}\] El problema para realizar este cálculo ya debe de ser evidente: no es posible contar cuántos fumadores hay en una población de más de 47 millones de habitantes. Y aunque fuera posible hacerlo, no es operativo; al finalizar semejante recuento, habrán nacido nuevos sujetos en la población, otros habrán fallecido y ciertos sujetos que no fumaban cuando fueron observados, ahora lo hacen, o al contrario, habrá fumadores que hayan abandonado esta adicción. Una solución, como ya se ha expuesto, es seleccionar una muestra que sea representativa de la población española y determinar la prevalencia muestral del tabaquismo. A partir de este estadístico3, mediante la aplicación de los métodos inferenciales apropiados, será cuando podremos decir algo acerca de la prevalencia del tabaquismo en la población.
El concepto de parámetro tiene implícito el hecho de que se trata de una cantidad constante. Sin embargo, las poblaciones -al menos las tangibles- son dinámicas, están sometidas a cambio permanentemente. El ejemplo anterior sobre el tabaquismo bien lo ilustra. Sin embargo, dado su tamaño, el cambio poblacional suele ser lo suficientemente lento como para que los parámetros que caracterizan a la población puedan considerarse constantes durante un periodo de tiempo limitado. Más ejemplos de parámetros son la edad media de la población, la proporción de hombres y mujeres, la proporción de personas obesas, etc. Enfaticemos que se trata de resúmenes numéricos y que no van a cambiar drásticamente de un día para otro.
Variable. Llamaremos así a cualquier característica que pueda variar de un elemento a otro de la población. Al tratar con poblaciones humanas, son variables la edad, el peso, la estatura, etc. Se trata de magnitudes que cambian -que varían- de un individuo a otro. También son variables el sexo, el grupo sanguíneo o si el sujeto fuma o no. Estos son ejemplos de magnitudes o de aspectos observables, que podemos recoger como información muestral para elaborar después las inferencias adecuadas sobre la edad media de la población, o su peso medio, o la distribución por sexos, o por grupos sanguíneos, etc. En los ejemplos presentados es inmediato apreciar que algunas variables van a tener una identidad numérica (la edad, el peso, la estatura), mientras que otras no (el sexo, el grupo sanguíneo, la condición de fumador). Esto lleva a considerar dos grandes tipos de variable: las variables categóricas o cualitativas, y las variables cuantitativas o numéricas. Las primeras se presentan con diferentes categorías o modalidades que en ningún caso tienen identidad numérica. Por ejemplo, la variable sexo es una variable categórica con dos modalidades o categorías {masculino, femenino}. La variable grupo sanguíneo es también una variable categórica con cuatro modalidades {A, B, AB, 0}. Cuando solo se presentan dos categorías se dice que la variable es binaria o dicotómica. Las variables binarias reciben especial atención en el ámbito de las Ciencias de la Salud. Además, tanto la variable sexo como grupo sanguíneo carecen de relación ordinal entre sus categorías -no se puede ser “más que”-. Este tipo de variables categóricas se dice que tienen escala nominal. En ellas, la única relación posible entre dos observaciones es la de equivalencia. Por ejemplo, se puede decir “tengo el mismo, o diferente, grupo sanguíneo que tu” (relación de equivalencia) pero no “tengo más, o menos, grupo sanguíneo que tu” (relación ordinal). Pero hay variables categóricas que sí pueden tener definida una relación ordinal entre sus modalidades, por ejemplo, tras la aplicación de un tratamiento se puede observar si el estado del paciente (esta es la variable) es peor, igual, o mejor que antes de recibirlo. Ahora, además de la relación de equivalencia “estoy igual que tu”, sí que es posible establecer la relación ordinal “estoy peor, o mejor, que tu”. Al manejar variables de tipo categorico, tanto en escala nominal como en la ordinal, es frecuente asignarles valores numéricos arbitrarios. En principio, esto no las convierte en numéricas, simplemente es una forma de codificación. Las variables numéricas o cuantitativas son aquellas cuya representación viene dada por una escala numérica. Ya no hablamos de categorías, sino de valores. Hay dos tipos de variables cuantitativas, las discretas, que toman valores en el conjunto de los números enteros (son recuentos), y las continuas, que toman valores en el conjunto de los números reales (son medidas). Por ejemplo, el número de hijos en una familia es una variable discreta -se habla de “cuántos hijos”, un recuento- y no es posible tener “medio hijo”, también lo es el número de recidivas de una enfermedad. Sin embargo, el peso o la estatura son variables de tipo continuo. Se trata de medidas en las que puede ser posible aportar algún decimal más de precisión si el instrumento de medida lo permite.
El tipo de la variable es clave para definir el tipo de tratamiento estadístico que es admisible. Pero una cosa es el tipo real de una variable y otra cosa es cómo se la trata. Un buen ejemplo de ello es la edad, ¿se trata de una variable discreta o continua?. La edad de una persona es el tiempo transcurrido desde el momento de su nacimiento hasta la actualidad, y si hay algo que es continuo en nuestro universo, eso es el tiempo. Sin embargo, es frecuente tratar a la edad a la edad de una persona como un valor discreto obtenido truncado -y no redondeando4- los años que tiene.
En cualquier caso, el ejemplo ilustra que siempre que se tiene una variable con alto contenido informativo, es posible “desperdiciar” parte de la información que contiene y tratarla como si perteneciera a un tipo con menor información. El mínimo contenido informativo lo presentan las variables binarias, no es posible dar menos información que si sí o si no se tiene determinada característica, mientras que las continuas son las de mayor contenido en información. Los cambios de métrica son posibles en el sentido de perder información. Una variable continua se puede discretizar para reducirla a valores enteros. A su vez, cualquier variable cuantitativa se puede categorizar para reducirla a clases o categorías que, en toda lógica, mantendrán una relación ordinal. Finalmente, cualquier variable se puede dicotomizar para convertirla en binaria. Pero estas pérdidas de información no deben hacerse gratuitamente. En la fase analítica de un estudio, se debe evitar esta reducción de información y manejar la máxima posible. Sin embargo, cuando se trata de aportar un resumen final, puede ser de interés basar la síntesis en un cambio de métrica para facilitar su comprensión.
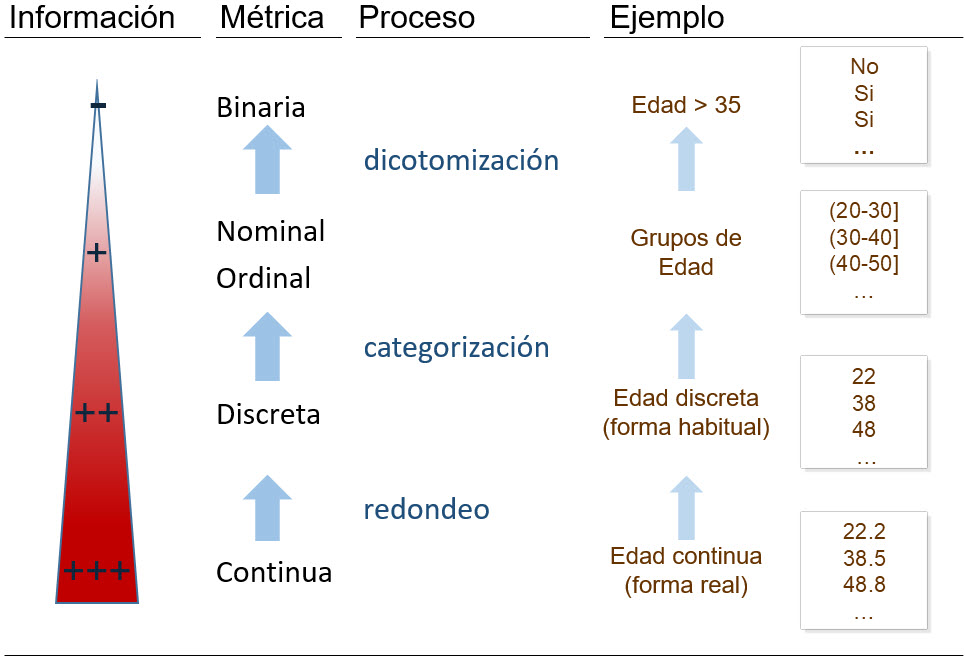
Resulta obvio que siempre es posible perder información pero no ganarla, así que invertir las flechas en la Figure 2.2 no es viable, no se puede sacar información de donde no la hay. Sin embargo, sí que hay salvedades. Una variable continua, en el fondo es una variable con una gran riqueza de valores posibles (se está considerando al conjunto de los números reales). Cuando una variable discreta presenta un recorrido suficientemente amplio, se puede asumir que imita al comportamiento de los números reales, y es frecuente tratarla como si fuera continua. Esto ocurre, por ejemplo, con la frecuencia cardiaca. El número de latidos por minuto tiene indiscutiblemente una métrica discreta. Sin embargo, la riqueza de valores posibles de esta variable es elevada. En reposo, la frecuencia normal es entre 50 y 100 latidos, mientras que durante el ejercicio físico se puede incrementar más del doble. Es por ello que, en muchos análisis, el análisis de la frecuencia cardiaca se aborda con métodos que son pertinentes para variables continuas, aunque en estos casos, suele ser conveniente ajustar el método analítico introduciendo una corrección por continuidad. Algo similar ocurre al manejar variables ordinales. Es común asignarles valores numéricos arbitrarios (siempre que respeten la relación ordinal y la magnitud diferencial entre categorías) y tratarlas como si se tratara de variables discretas. Más adelante surgiran ejemplos ilustrativos de estas situaciones.
Otro aspecto que cabe mencionar es el hecho de que, dado que los métodos de medida tienen una precisión limitada, en el fondo, todas las medidas son discretas, y esto efectivamente, es así. Cuando se mide la estatura de una persona, se puede decir que esta mide 1,72 metros -con toda la apariencia de ser una medida continua, ya que este valor es un número real-, o bien que mide 172 centímetros. Si el metro usado para medir no permite cuantificar los milímetros, la medida obtenida, en el fondo, es una magnitud discreta, independientemente de los cambios de unidades que podamos considerar. Sin embargo, es posible aplicar el argumento presentado en el párrafo anterior, dado que en estos casos, la riqueza de valores posibles va a ser alta, la aproximación a la continuidad resulta adecuada (y mejora cuanto mayor sea el tamaño muestral).
2.1.1 Magnitudes físicas y constructos psicológicos
La investigación en el ámbito de las Ciencias de la Salud suele implicar el manejo de variables tales como el sexo, la edad del sujeto, el peso, la glucemia, la tensión arterial, etc. Todas estas variables son directamente observables o bien medibles mediante los instrumentos de medida apropiados. Sin embargo, hay otro tipo de aspectos, como la ansiedad, la calidad de vida, el estrés, etc. en donde la cuantificación de la intensidad con que se presentan no es nada sencilla, ya que no existen aparatos de medida similares a los que permiten cuantificar las magnitudes físicas o químicas. Este tipo de variables suelen definirse como constructos, conceptualizaciones emanadas de una teoría, y es la Psicometría la ciencia que se ocupa de todo lo relacionado con su medida. Los instrumentos de medida construidos por esta disciplina tienen la forma de test, o cuestionario, aunque es habitual aludir a ellos como “instrumentos”. En su elaboración, surge un problema fundamental que es la construcción de las escalas de medida. Hay diferentes metodologías, pero la más sencilla, y seguramente la más utilizada, es el de escalas sumativas de tipo Likert. En este formato, el cuestionario consta de una serie de ítems cada uno de los cuales se presenta como un enunciado al que el sujeto que responde debe dar un nivel de intensidad (cada ítem constituye por tanto una variable de tipo ordinal). La escala presentada suele referirse al nivel de acuerdo, a la frecuencia o a la importancia que se da al enunciado del ítem.
- acuerdo: totalmente en desacuerdo / en desacuerdo / indiferente / de acuerdo/ totalmente de acuerdo
- frecuencia: nunca / raramente / ocasionalmente / frecuentemente / casi siempre
- importancia: irrelevante / de poca importancia / normal / importante / muy importante
La idea es que un constructo no va a poder ser descrito por un solo ítem, de modo que se presentan cierto número de ellos que deben medir el rasgo en cuestión con la misma intensidad. A cada nivel de la escala de cada ítem se asocia un valor y la medida final se obtiene como la suma de todos los valores con que se ha respondido a cada uno de los ítems. En el ámbito de las Ciencias de la Salud podemos encontrar numerosos instrumentos de este tipo. Por ejemplo, el test de Zarit, constituido por 22 ítems orientados a evaluar el nivel de sobrecarga del cuidador, o la escala Norton, con 14 ítems para evaluar el nivel de integridad cutánea.
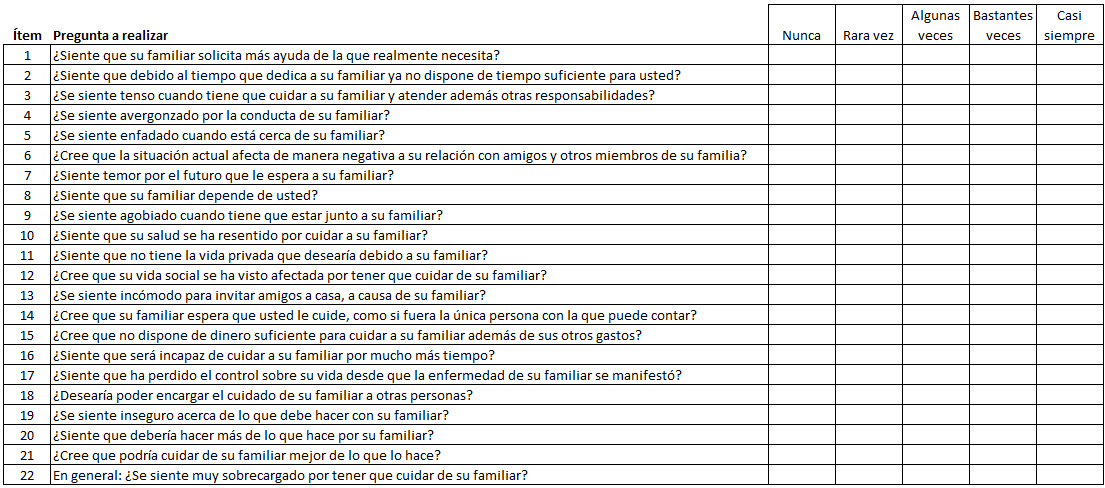
El test consta de 22 ítems cada uno de los cuales se puntúa de 0 a 4 puntos (método anglosajón) o de 1 a 5 (método español). En el primer caso, la puntuación total del test es de 0 a 88 puntos, mientras que en el segundo es de 22 a 110. Es habitual que la puntuación final obtenida se categorice para dar un diagnóstico. Las categorías son:
- < 46 (o < 68 en Esp.) …… No hay sobrecarga
- 46-56 (o 68-78 en Esp.) .. Sobrecarga moderada
- > 56 (o >78 en Esp.)…….. Sobrecarga intensa
El hecho de que existan dos criterios de puntuación, pone de manifiesto la arbitrariedad en la asignación de valores cuantitativos a los niveles de intensidad en la escala. Ninguno de los criterios es superior al otro, los dos respetan el orden y la distancia conceptual entre los niveles de frecuencia.
Cuando se trata con instrumentos de medida de magnitudes físicas -por ejemplo, un metro para medir la estatura-, el instrumento suele presentar una validez implícita, es decir, es indiscutible que un metro permite medir distancias. Sin embargo, al elaborar un instrumento psicométrico, su validez es algo que hay que comprobar. Es decir, se trata de probar que el instrumento mide realmente la intensidad con la que se presenta el rasgo para el que se ha diseñado, y no otra cosa. Así mismo, igual que ocurre con la precisión de los instrumentos físicos de medida, los psicométricos también van a presentar un nivel de fiabilidad, es decir, si se mide a los mismos sujetos en las mismas circunstancias, hasta qué punto se reproducen los mismos resultados. La elaboración de nuevos cuestionarios implica analizar estos aspectos, lo que requiere del uso de la metodología estadística apropiada.
2.2 Lecturas complementarias
En el capítulo 1 del texto de (martin2004?) se amplían los argumentos expuestos aquí sobre la necesidad de la Estadística en las Ciencias de la Salud.
Un manual práctico para la elaboración de cuestionarios basados en escalas de tipo Likert es el texto de (morales2003?). (agresti2022?) (azorin1986?) (crawley2013?) (lewontin1984?) (martin2004?) (mcshea2010?) (morales2003?)
Variabilidad: estado o grado de ser variable. Variable: del latin variabĭlis, que varía o puede variar, que puede ser cambiante, inconstante.↩︎
Hay situaciones en donde el tamaño poblacional es limitado. Estos casos, que requieren cierta modificación de la metodología, se quedan fuera del ámbito de este texto. En adelante, supondremos siempre que las poblaciones son inmanegablemente grandes.↩︎
Un estadístico es cualquier función real (medible) de los valores muestrales.↩︎
Habitualmente, cuando alguien tiene 23 años y 9 meses (esto son 23,75 años en escala decimal) se dice que tiene 23 años (se truncan los decimales) y no 24, que sería el redondeo correcto al entero más próximo.↩︎