
|
|
|
Proyecto Docente "Software Específico para Bibliometría, Evaluación de la Ciencia y Vigilancia Tecnológica" |
Redes 2005 |
Análisis de Redes Tecnocientíficas |
|
|
||
Construcción de agrupaciones, temas o subredes: actores temáticos
La matriz de asociaciones normalizada es la matriz de adyacencia del grafo que representa la red. Cada vértice de este grafo es un descriptor y cada índice de equivalencia entre cada dos descriptores es la ponderación de los arcos que une estas parejas de vértices. En principio sería reconstruible directamente la red imponiendo un umbral mínimo o bien realizar una representación gráfica en dos o tres dimensiones usando un análisis MDS o bien una estructura jerarquizada del tipo dendrograma. Se ha comprobado que posibilidades como éstas no son óptimas para nuestros propósitos (COURTIAL, J. P., 1986), siendo necesario establecer un algoritmo o algoritmos que sean capaces de:
- Extraer de la red ciencimétrica (excesivamente extensa por el elevado número de vértices y enlaces) aquellas agrupaciones o subredes significativas. Estas subredes representarían los temas de investigación y definirían los actores que forman la red global.
- Ofrecer una estabilidad suficiente de los esqueletos (actores-red) frente a factores negativos como errores en la indización y tamaño de la muestra.
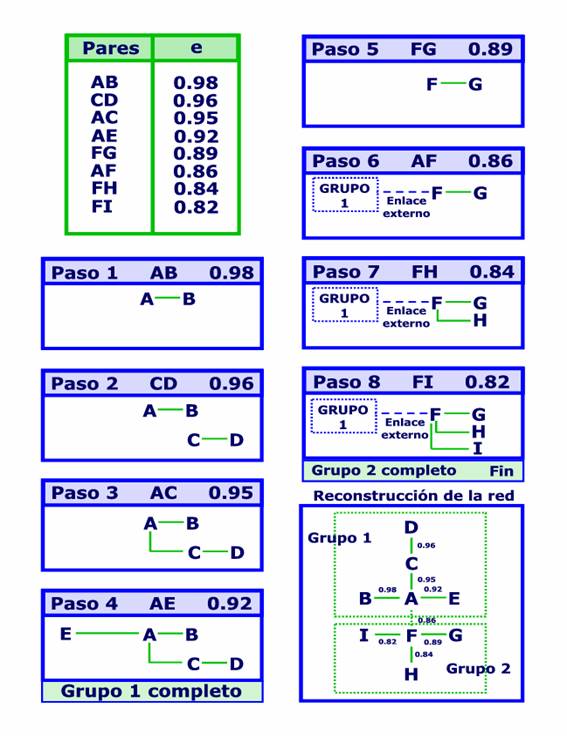
Figura 1.- Algoritmo de clasificación por enlace simple
- Poder controlar perfectamente las dimensiones de las subredes que definen los actores (número de palabras y umbral de enlace de los temas)
- Capacidad de calcular parámetros que cuantifiquen los actores y los definan según suposición estratégica y poder seguir su evolución temporal o dinámica.
- En definitiva, que conceptos de la teoría actor-red como las traducciones puedan ser accesibles a un simple cálculo con un microordenador.
Leximappe posee dos algoritmos, ejecutables por sendos módulos independientes: programa COMPS.EXE y programa STAR.EXE. Sus denominaciones son las siguientes: Algoritmo de clasificación por enlace simple (COMPS.EXE) y algoritmo de agrupación por centros simples (STAR.EXE) (WHITTAKER, J., 1988). Redes emplea el algoritmo de agrupación por centros simples, ya que identifica mejor los centros de interés.
a) Algoritmo de clasificación por enlace simple. Los elementos de la matriz de asociaciones son ordenados en una lista decreciente según su índice de equivalencia. Esta lista está formada tan solo por aquellas palabras que tengan una ocurrencia mínima y pares de asociaciones también con una co-ocurrencia mínima preestablecidas. El programa recorre la lista desde el principio y va construyendo dobletes, tripletes, etc. de palabras asociadas de forma que suministra un grafo conexo que no exceda de un valor máximo de palabras preestablecido (por ejemplo 10 ó 15) Cada vez que se obtiene un grafo, elimina las palabras de éste de la lista y comienza el proceso de construcción de nuevos grafos hasta agotar el total de palabras disponibles. La Figura 1 es un ejemplo extraido de (COURTIAL, J. P., 1990) que explica los pasos que se siguen usando este algoritmo para la formación de agrupaciones con un máximo de 5 palabras y la reconstrucción posterior de la red.
b) Algoritmo de agrupación sobre centros simples. Este algoritmo también ordena los pares de asociaciones por orden decreciente de índice de equivalencia y sólo pueden formar parte de esta lista las palabras con una ocurrencia mínima y los pares con una co-ocurrencia mínima establecidas previamente. El ordenador inicializa un contador para cada descriptor y comienza a recorrer la lista desde el principio incrementando el contador de las palabras que van apareciendo. Cuando el contador de una palabra alcanza un valor igual al número de palabras máximo estipulado para los temas menos uno, el algoritmo toma esta palabra como centro de una agrupación. El conjunto resultante estará formado por las uniones de esta palabra central y todas aquellas que se han asociado con ella. El resultado es una estructura en forma de estrella. Las palabras que han aparecido se eliminan de la lista y se comienza de nuevo el proceso para generar más agrupaciones. Si después de recorrer toda la lista ningún contador llega al valor máximo preestablecido, éste se disminuye en tantas unidades como sea necesario para formar una nueva agrupación. El proceso finaliza cuando el valor máximo del contador disminuya hasta un valor mínimo preestablecido o se terminen todas las palabras de la lista ordenada de pares.
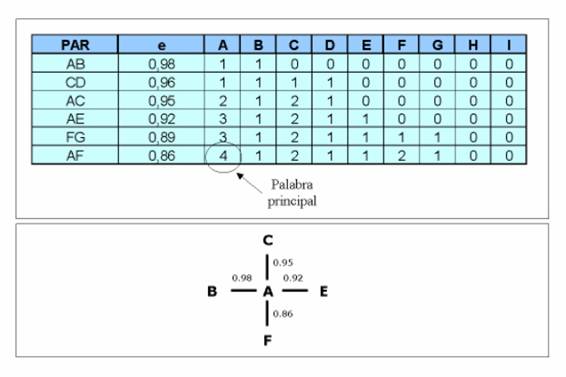
Figura 2.- Algoritmo de agrupación sobre centros simples
Este algoritmo tiene la ventaja, frente al anterior, de que nos asegura que cualquier subred obtenida contiene al menos una palabra unida a todas las demás. Esta palabra principal nos va a facilitar la identificación del tema de investigación.
La figura 2 explica el proceso de agrupación sobre centros simples para el ejemplo de la Figura 1. Se observa que el resultado es diferente ya que resulta un solo grupo con una estructura en estrella que será identificado mediante la palabra A.
Ambos métodos pueden dar resultados algo diferentes a la hora de definir las subredes, pero al reconstruir la red global, el resultado es siempre el mismo.
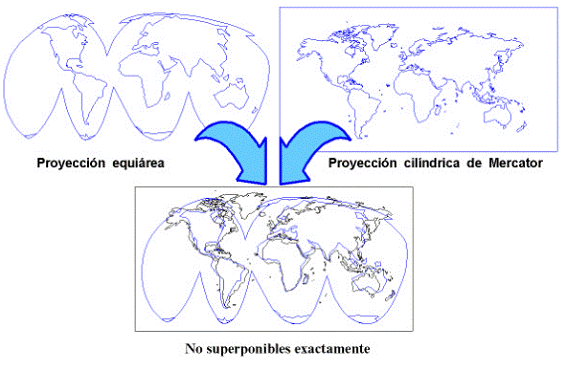
Figura 3.- Influencia del tipo de proyección en los mapas
La propia esencia de las redes ciencimétricas y sociocognitivas es la de la presencia de fronteras difusas, por lo que no es de extrañar que no sea posible definirlas exactamente. Según el algoritmo utilizado, trazaremos más hacia un lado o hacia otro de la frontera difusa, la línea divisoria que nos servirá de referencia, pero debe entenderse que esta línea es sencillamente una guía para adentrarnos de forma simplificada en el estudio de las redes que de por sí son muy complejas. Este fenómeno se asemeja al que aparece cuando un geógrafo intenta representar el globo terrestre en un papel. Para ello puede utilizar diversos tipos de proyecciones que no son superponibles exactamente unas sobre otras, presentándose un corrimiento de fronteras y costas. En la Figura 3 hemos superpuesto dos mapas de la tierra, uno según la técnica de proyección equiárea y el otro según Mercator. Se comprueba que, anque ambos mapas son perfectamente válidos y representan muy bien la superficie terrestre, no son exactamente coincidentes. La razón es muy sencilla, se pretende representar en un plano la superficie que rodea una esfera. De forma análoga, cuando se realizan mapas de la Ciencia , se pretende representar también sobre un plano, las relaciones complejas y multidimensionales de una red de difícil representación. Por ello, los algoritmos nunca serán perfectos, tendrán pequeñas diferencias entre ellos, pero sí se podrán considerar perfectamente válidos. Sobre estos mapas de la Ciencia se podrá navegar sin dificultades, igual que lo hace un marino por todos los océanos de la tierra, independientemente del tipo de proyección que emplee su mapa.
Referencias:
Courtial, J. P. (1986). Technical issues and developments in methodology. En M. Callon, J. Law, & A. Rip (eds), Mapping the dynamics of science and technology: Sociology of science in the real world . London: MacMillan Press LTD.
Courtial, J. P. (1990). Introduction a la scientométrie: de la bibliométrie a la veille techonologique. Paris : Anthropos.
Co-word analysis: The Keele programs. (1988). Reino Unido: Universidad de Keele.