
|
|
|
Proyecto Docente "Software Específico para Bibliometría, Evaluación de la Ciencia y Vigilancia Tecnológica" |
Redes 2005 |
Análisis de Redes Tecnocientíficas |
|
|
||
Medida de los enlaces
La fuerza con que se ligan los vértices de un grafo puede ponderarse mediante dos tipos de magnitudes, a saber:
a) Coeficientes de similitud.
b) Coeficientes de disimilitud.
Un coeficiente de similitud es mayor conforme más parecidos o más ligados están dos vértices. En cambio, los coeficientes de disimilitud se incrementan cuanto más diferentes o menos ligados están estos dos vértices. Son muchos los coeficientes de ambos tipos definidos por la literatura, por lo que sólo haremos un repaso de los más usuales.
Entre ellos, los principales son las distancias. Sea C una matriz de datos n x k, donde n representa n puntos y k las dimensiones del espacio (EGGHE, L. y ROUSSEAU, R., 1990)
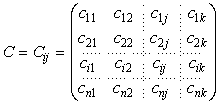
Ecuación 1
Las filas, desde 1 hasta n, representan los puntos y las columnas, desde 1 hasta k, las dimensiones. El número de dimensiones de un punto es igual al número de parámetros utilizados para definirlo. Esta distribución de filas y columnas puede aparecer invertida en autores de origen anglosajón.
Sea X el conjunto {C1, C2, ..., Cn} de estos n puntos. La función distancia es una función
![]()
Ecuación 2
que cumple las siguientes propiedades.
1.- La distancia entre dos puntos es nula si y solo si los dos puntos son coincidentes.
![]()
Ecuación 3
O bien, la distancia de un punto consigo mismo es siempre nula.
2.- La distancia entre dos puntos cumple la propiedad simétrica. La distancia del punto x al punto y es igual a la distancia del punto y al punto x.
![]()
Ecuación 4
3.- Las distancias entre tres puntos cumplen la "desigualdad triangular".
![]()
Ecuación 5
Es decir, el camino más corto entre dos puntos es la línea recta.
El conjunto X con la función distancia se denomina "espacio métrico". Según se defina la distancia, tendremos distintos espacios métricos.
a) Espacio métrico trivial.
Una distancia es trivial cuando es nula para un punto consigo mismo y 1 para con cualquier otro punto.
![]()
Ecuación 6
![]()
Ecuación 7
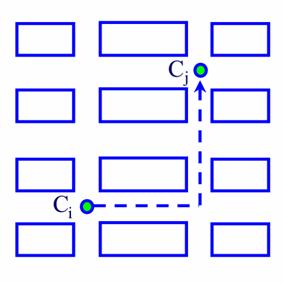
Figura 1.- Espacio métrico de bloques
b) Espacio métrico de bloques.
Una distancia de este tipo es semejante a la que habría que recorrer en una ciudad de calles paralelas y perpendiculares para ir de un punto a otro, tal como se muestra en la Figura 2. Se define matemáticamente como:

Ecuación 8
c) Espacio métrico euclidiano.
Sin ninguna duda es el espacio métrico más usual. Se define de la siguiente forma:
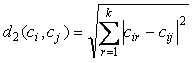
Ecuación 9
d) Espacio métrico de Minkowski
Es una generalización de los espacios tipo bloque y euclidianno, según el parámetro p valga 1 ó 2 respectivamente:
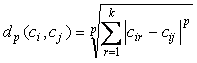
Ecuación 10
e) Espacio métrico de Chebycheff
Es el caso de un espacio métrico de Minkowski en el que el parámetro p se hace infinito:
![]()
Ecuación 11
![]()
Ecuación 12
d) Espacio métrico de Hausdorff – Besicovitch. Dimensión Fractal
Este tipo de espacio ya se ha comentado ampliamente en la teoría de los fractales. Su definición se substenta en la Ley de Zipf , siendo la dimensión fractal , D, de carácter incluso fraccionario, la inversa del exponente de esta ley, según se ha visto en la Ecuación 1‑105:
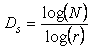
Ecuación 13
Las distancias se utilizan con frecuencia cuando el grafo se va a visualizar en forma de dendrograma. También son frecuentes en sistemas de recuperación de la información. Para el uso de las distancias es importante que los valores de todas las dimensiones oscilen en rangos parecidos. Si una de las dimensiones posee valores exageradamente altos respecto a las otras, las oscilaciones de éstas últimas quedarían ocultadas por las oscilaciones de la dimensión sobrevalorada. Otro problema de las distancias (salvo la trivial) es que es que no están normalizadas, ya que su límite superior no está limitado, por ser infinito.
Las distancias euclidianas se han usado en estudios de muy diversa naturaleza. (CARPENTER, M. P. y NARIN, F., 1973) analizan 288 revistas de física, química y biología molecular. Las revistas las agruparon usando distancias euclidianas, teniendo la precaución de normalizar la matriz de datos usando referencias expresadas en tantos por ciento. En otro trabajo y mediante el programa STRUCTURE se han determinado las posiciones relativas de los autores que escriben sobre ciencimetría dentro de la red generada por la revista Scientometrics (WOUTERS, P. y LEYDESDORFF, L., 1994).
Los coeficientes o índices de similitud más usuales consideran dos conjuntos con un cierto nivel de intersección (Figura 2) La similitud entre ambos conjuntos depende siempre del tamaño de esa intersección bien respecto del tamaño total de los dos conjuntos o bien de parte de ellos.
a) Indice de inclusión.
Este índice nos mide el nivel de intersección respecto del conjunto más pequeño. El valor obtenido se sobrevalora muchísimo si uno de los conjuntos es muy pequeño respecto del otro. Se define mediante la ecuación:
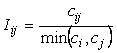
Ecuación 14
Este índice ha sido utilizado especialmente por su carácter asimétrico por (TODOROV, R. y WINTERHAGER, M., 1990) en la cartografía de la geofísica en Australia XE "Australia" usando un análisis de coencabezamientos de materias. Ofrece buenos resultados usando un análisis escalar multidimensional, MDS, en dos dimensiones combinado con un análisis de agrupaciones (programa ASCAL)
Resultados análogos se obtienen en el campo de la biotecnología usando también el análisis de co-encabezamientos de materias con el programa ASCAL (MCCAIN, K. W., 1995). Los mapas obtenidos son equiparables a los que obtuvieron Rip et al. con la versión primitiva de Leximappe (RIP, A. y COURTIAL, J. P., 1984). Es interesante destacar que se obtengan resultados parecidos usando un lenguaje controlado (McCain) y un lenguaje natural a base de descriptores (Rip)
El índice de inclusión es también utilizado, lógicamente, por Tijssen et al. cuando comparan la primera versión de Leximappe con el análisis MDS (TIJSSEN, R. J. W. y VAN RAAN, A. F. J., 1989) y (RIP, A. y COURTIAL, J. P., 1984).
Braam et al. en su análisis combinado de co-citas y co-palabras, utilizan sin embargo el índice de inclusión como medio para recuperar información de una base de datos previamente tratada con un análisis de agrupaciones (BRAAM, R. R.; MOED, H. F. y VAN RAAN, A. F. J., 1991a), (BRAAM, R. R.; MOED, H. F. y VAN RAAN, A. F. J., 1991b).
b) Indice de Jaccard.
Este índice es de los más populares. Se define mediante la ecuación:
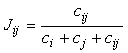
Ecuación 15
Como se puede observar es el cociente de la intersección partido entre la suma de todo lo no común. Es al contrario del índice de inclusión, un índice simétrico, y como aquel, sus valores oscilan entre 0 y 1. Cuando la intersección es nula, Jij=0, y cuando los conjuntos son idénticos, Jij=1.
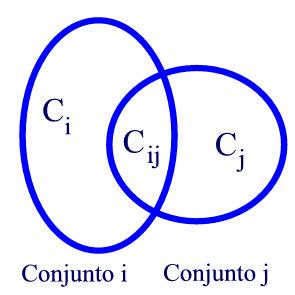
Figura 2.- Intersección de conjuntos similares
Durante los años 1.973 y 1.974, el SCI utilizó el índice de Jaccard para determinar los frentes de investigación XE “Investigación” . Posteriormente fue abandonado en favor del coseno de Salton.
También son muy numerosos los estudios realizados con el índice de Jaccard como los anteriormente citados de co-encabezamientos (TODOROV, R. y WINTERHAGER, M., 1990), y de palabras asociadas QUOTE "(RIP, A. y COURTIAL, J. P., 1984),(RIP, A. y COURTIAL, J. P., 1984). Small et al. lo utilizan también como coeficiente de similitud en un análisis de contextos con agrupación de co-citas (SMALL, H. y GREENLEE, E., 1980). Recientemente ha sido utilizado en la cartografía del campo redes neuronales (VAN RAAN, A. F. J. y TIJSSEN, R. J. W., 1993).
c) Coseno de Salton.
Usado por el SCI desde 1.975, se define como:

Ecuación 16
Sus valores oscilan, como en el de Jaccard entre 0 y 1. El coseno de salton da normalmente valores de similitud más elevados que el de Jaccard, variando el cociente Sij/Jij entre 1 e infinito, aunque la mayor parte de los casos es de 2 (HAMERS, L. et al., 1989).
Si bien el coseno de Salton se utiliza en la ponderación de grafos (BRAAM, R. R.; MOED, H. F. y VAN RAAN, A. F. J., 1991a), (BRAAM, R. R.; MOED, H. F. y VAN RAAN, A. F. J., 1991b), su aplicación más extendida se encuentra en el campo de la recuperación de la información.
Otros coeficientes de similitud importantes son el índice de equivalencia y el índice de transformación, que al ser propios de Leximappe, serán estudiados más profundamente en el capítulo de las Palabras Asociadas.
Referencias:
Braam, R. R., Moed, H. F., & Van Raan, A. F. J. (1991a). Mapping of science by combined co-citation and word analysis. I. Structural aspects. Journal of the American Society for Information Science, 42(4), 233-251.
Braam, R. R., Moed, H. F., & Van Raan, A. F. J. (1991b). Mapping of science by combined co-citation and word analysis. II. Dinamical aspects. Journal of the American Society for Information Science, 42(4), 252-266.
Carpenter, M. P., & Narin, F. (1973). Clustering of scientific journals. Journal of the American Society for Information Science, (Nov-Dic), 425-436.
Egghe, L., & Rousseau, R. (1990). Introduction to informetrics: quantitative methods in library, documentation and information science. Amsterdam, etc.: Elsevier.
Hamers, L., Hemeryzk, Y., Herweyers, G., Janssen, M., Keters, H., Rousseau, R., & Van Houtte, A. (1989). Similarity measures in scientometric research: the Jaccard index versus Salton's cosine formula. Information Processing & Management, 25, 315-318.
McCain, K. W. (1995). The structure of biotechnology R & D. Scientometrics, 32(2), 153-175.
Rip, A., & Courtial, J. P. (1984). Co-word maps of biotechnology: an example of cognitive scientometrics. Scientometrics, 6(6), 381-400.
Small, H., & Greenlee, E. (1980). Citation context analysis of a co-citation cluster: recombinat-DNA. Scientometrics, 2(4), 277-301.
Tijssen, R. J. W., & Van Raan, A. F. J. (1989). Mapping co-word structures: a comparison of multidimensional scaling and leximappe. Scientometrics, 15(3-4), 283-295.
Todorov, R., & Winterhager, M. (1990). Mapping Australian geophysics: a co-heading analysis. Scientometrics, 19(1-2), 35-56.
Van Raan, A. F. J., & Tijssen, R. J. W. (1993). The neural net of neural network research: an exercise in bibliometric mapping. Scientometrics, 26(1), 169-192.
Wouters, P., & Leydesdorff, L. (1994). Has Price's dream come true: is scientometrics a hard science? Scientometrics, 31(2), 193-222.